Sling vs dlt SQL connector Benchmark: Spend 3x Less, Load Faster with dlt
We compared dlt and Sling for data ingestion performance, cost, and flexibility. See how they stack up and which might suit your data needs best.
 Adrian Brudaru,
Adrian Brudaru,
Co-Founder & CDO Aman Gupta,
Aman Gupta,
Data Engineer Shreyas Gowda,
Shreyas Gowda,
Working Student
Here at dltHub, we take data ingestion seriously. When we heard Dagster’s community rave about Sling, we decided to try it ourselves and compare it to our SQL source.
TLDR
- dlt leads across the board: fastest loads (PyArrow, ConnectorX), low CPU + RAM usage (3-4x less hardware cost), full feature, no license fees.
- More control out-of-the-box: fine-grained memory management, hooks, chunking, parallelism, all open-source (Sling puts most behind paywalls).
- One Python-native engine for SQL, APIs, and files, ideal for Python-centric data teams who want a single, extensible ingestion layer.
Introducing dlt and Sling
dlt: Open-source Python library for building robust and scalable data pipelines to extract and load data.
Sling: Data movement and integration platform built around low-code ETL pipelines to simplify and streamline data operations.
Comparing dlt and Sling
1. Implementation
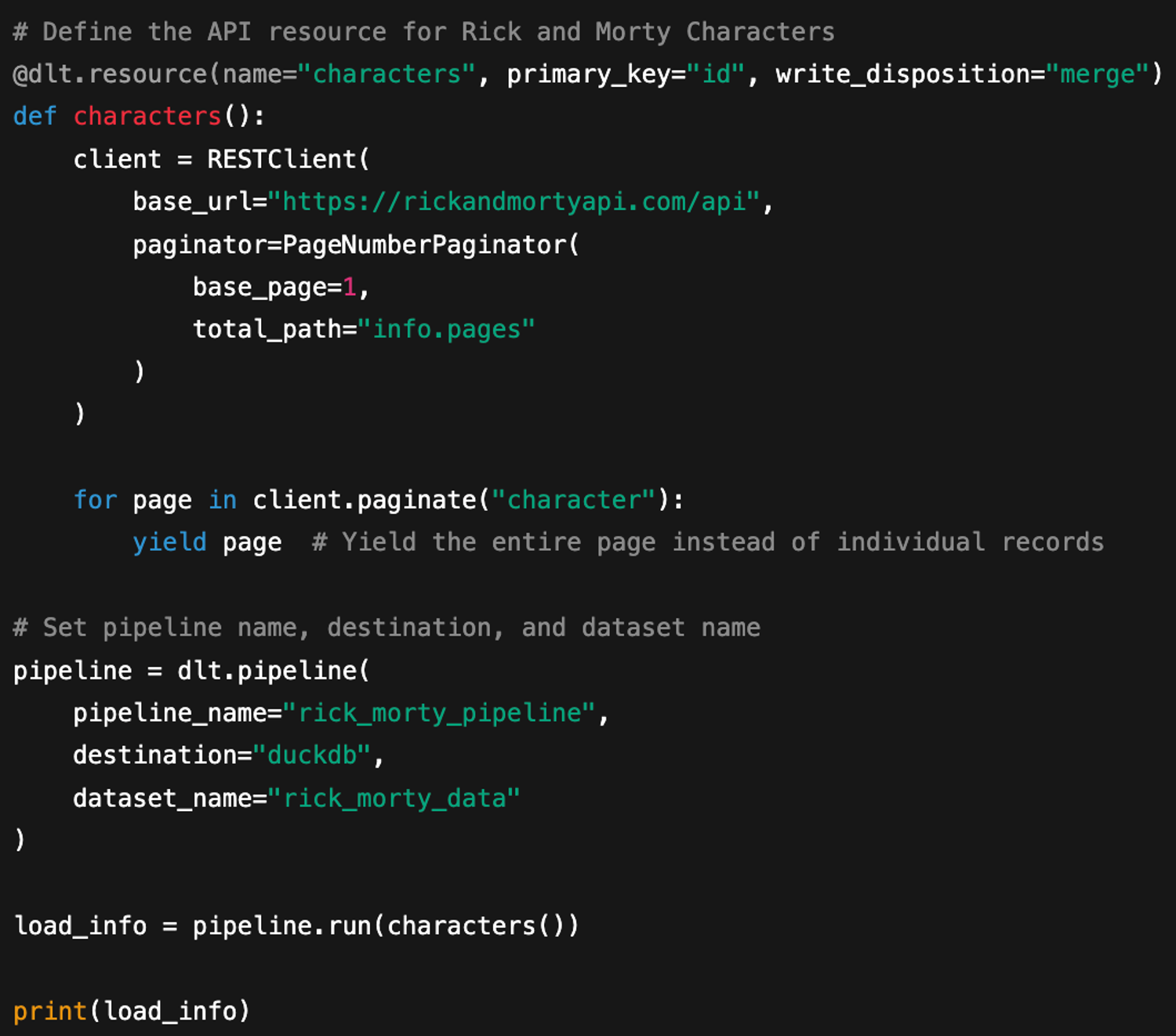
dlt is a code-first ETL library that emphasizes programmable data pipelines, schema evolution management, and developer-centric automation, providing flexibility and control through direct code-based interactions:
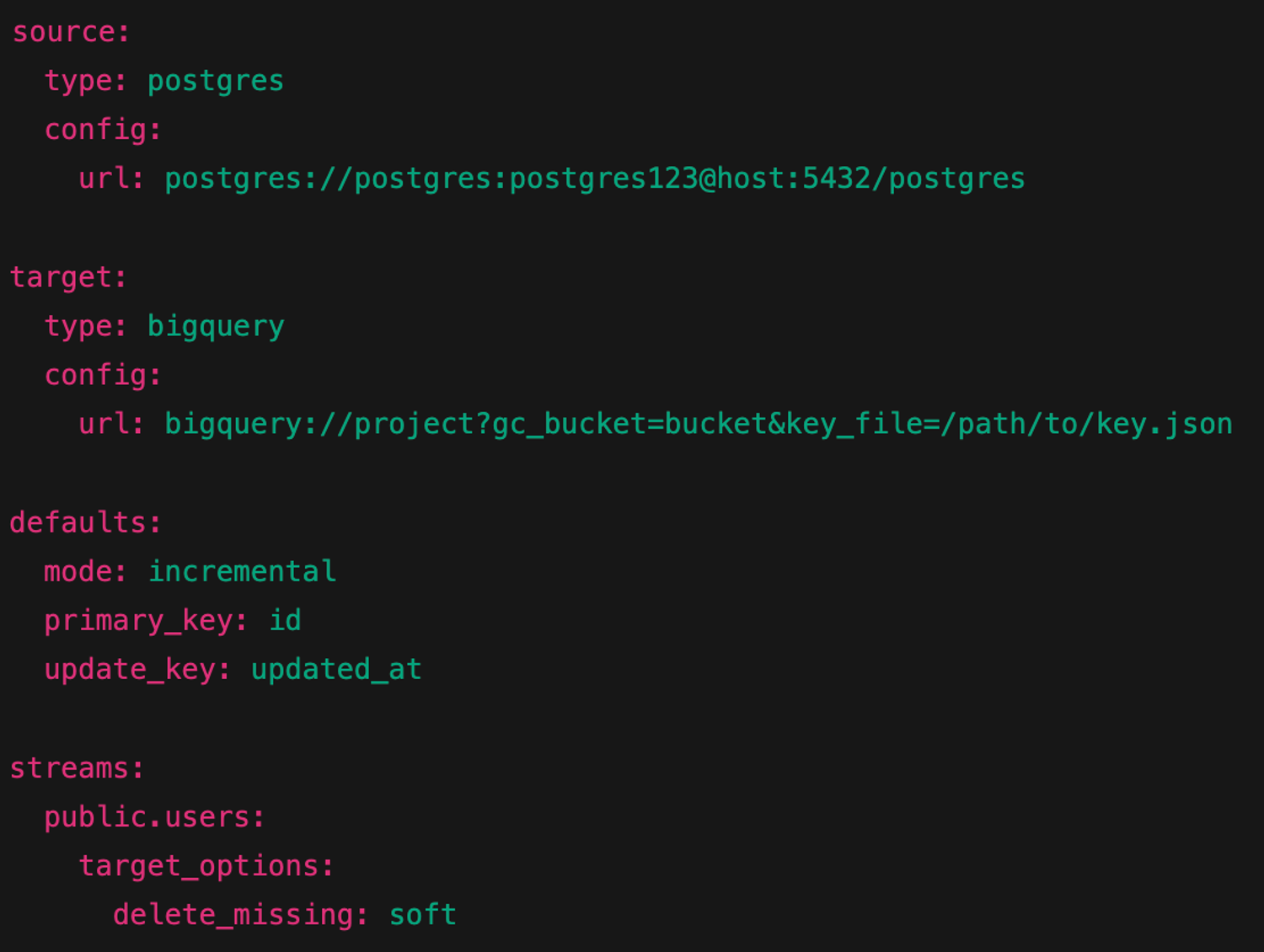
Sling is a configuration-first ETL tool that emphasizes rapid pipeline development through YAML-based declarative configurations and visual interfaces. This approach reduces manual coding effort, though it may offer less flexibility and direct control compared to code-first approaches:
2. Connector Ecosystem
| Category | dlt | Sling |
|---|---|---|
| DB/Storage connectors | 30+ DBs, 5 native storage connections | 22 DBs, 11 native storage connections |
| SaaS/API connectors | Yes | No |
| Analytics destinations | DBs, Vector DBs (Weavite, LanceDB, Qdrant), Delta, Iceberg | DBs, DuckLake, Iceberg |
| Extensibility | Custom Destinations, OpenAPI generator | YAML/hooks |
| Filesystem | Yes | Yes |
- Connector breadth: dlt offers 60+ pre-built source coverage.
- SaaS/API access: dlt removes the need for custom workarounds.
- Analytics destinations: dlt unlocks one-click ML and advanced analytics destinations.
- Extensibility model: dlt’s code-first approach empowers deeper customization.
Overall, dlt trades minimal setup for a highly flexible, end-to-end code ecosystem, while Sling stays lean for straightforward DB-to-storage replication.
3. Performance
Our comprehensive testing used the TPCH dataset (≈ 9.74 GB) across six configurations to compare raw throughput and resource efficiency.
Raw TPCH Benchmark Results
Time, memory, and CPU usage for each tool on the full TPCH load.
| Tool | Runtime | Avg Memory | Avg CPU | Notes |
|---|---|---|---|---|
| dlt ConnectorX | 10m 51s | 8.9 GB | 10.9% | Fastest but memory-intensive |
| Sling Pro | 14m 16s | 1.4 GB | 49.4% | Fast but CPU-intensive |
| dlt PyArrow | 15m 07s | 1.5 GB | 12.5% | Balanced efficiency |
| dlt Pandas | 17m 41s | 2.0 GB | 15.1% | Reliable baseline |
| Sling Non-Pro | 19m 34s | 1.0 GB | 35.7% | Budget option |
| * dlt SQLAlchemy | 82m 39s | 2.9 GB | 41.9% | Slower option |
dlt offers multiple SQL backends that skip normalisation and use OSS technologies for fast transfer: ConnectorX, PyArrow and Pandas. dlt also offers its default backend (on top of SQLAlchemy) that runs an additional row-by-row typing process that is useful for processing JSON.
For SQL loading, you should skip the SQLAlchemy backend, unless your SQL data is mostly JSON that needs to be typed and flattened into separate tables.
For dlt, we used default performance configuration. You can speed up dlt as exemplified in this benchmark.
In these benchmarks you can see a few interesting points
- dlt with pyarrow offers the best mix of performance and cost. It could be tweaked further with dlt’s performance tuning - for example, if transfer throughput is not limited we can increase parallelism to load faster at the cost of using more CPU.
- In Open Source, Sling is slower than all dlt backends.
- Sling and Sling pro both require about 3x more CPU minutes than dlt backends
- ConnectorX backend is the industry fastest but requires a lot of memory.
- PyArrow backend offers great speed without the shortcomings of ConnectorX, making it the best option for production pipelines.
- SQL alchemy backend is slow not because something’s wrong, but because it reflects a different process, where data is typed and normalised row by row - this backend is not recommended for SQL where data is typed, but for APIs where weakly typed JSON has to land in strongly typed destinations.
- The Sling Pro vs Sling uses the exact same amount of CPU minutes, suggesting the speed difference may occur due to parallelisation. dlt offers parallelisation out of the box that you can tweak to achieve similar speed-ups at the cost of CPU, until the limit of your network and clients throughput.
4. Cost
We calculated compute and memory costs using e2-standard-4 (4 vCPUs, 16 GB Memory) and GB-hour rates, and amortized license fees over 30 monthly runs to show the per-job cost of a single daily execution.
| Tool | Compute Cost | Memory Cost* | License Cost* | Total per Job |
|---|---|---|---|---|
| dlt PyArrow | $0.039 | $0.020 | $0 | $0.059 |
| dlt Pandas | $0.053 | $0.024 | $0 | $0.077 |
| dlt ConnectorX | $0.024 | $0.110 | $0 | $0.134 |
| Sling Non-Pro | $0.139 | $0.013 | $0 | $0.152 |
| Sling Pro | $0.172 | $0.017 | $1.63 | $1.829 |
dlt runs cost under $0.06 per job with PyArrow with no license fees, whereas Sling Pro clocks in at $1.83 per run, making dlt over 12× cheaper per daily pipeline execution.
5. Schema Evolution
| Scenario | dlt | Sling |
|---|---|---|
| Type widening (int→string) | Automatically creates variant columns | Needs manual intervention |
| Type narrowing (string→int) | Coerces int values to string | Coerces int values to string |
| New columns | Auto-added | Auto-added |
| Nested objects | Normalized | Normalized |
| Nested arrays | Automatically creates separate tables | Stored as a JSON column |
| New Tables | Auto-added | Auto-added if wildcard stream is used |
dlt automatically adapts to schema changes, widening types, coercing types, optionally normalizing objects/arrays, adding columns, and registering new tables.
Sling only handles type narrowing, object flattening, and new columns out of the box, leaves arrays as JSON, and requires wildcards or manual transforms for other changes.
6. Incremental Loading
| Feature | dlt | Sling Free | Sling Pro |
|---|---|---|---|
| Incremental Modes | Append, Replace, Merge, SCD2, Cursor-based | Append, Upsert, Incremental and Backfill - Custom SQL | State based |
| Delete Handling | SCD2 tracks created and deleted at | Soft delete tracks deleted at | Soft delete tracks deleted at |
| Cursor Tracking | Yes | Custom logic | Custom logic |
| Custom SQL Support | Yes | Yes | Yes |
| Time-Based Partitioning | Limited native support | Yes | Yes |
| Backfill | Yes | Yes | Yes |
| SCD2 Support | Built-in via merge | No - requires workaround using custom SQL or hooks | No |
| Lag/Attribution Window | Yes | No - requires workaround using custom SQL or hooks | No |
dlt delivers the most comprehensive incremental toolkit, append, replace, merge (with SCD2), and cursor modes; merge‑based deletes; cursor tracking; custom SQL; and lag/window support.
Sling Free and Pro cover append/upsert/backfill, native soft/hard deletes, and time‑based partitioning, but lack merge/SCD2 modes, cursor tracking, and lag windows.
7. State Management
| Feature | dlt | Sling Free | Sling Pro |
|---|---|---|---|
| State storage | Built‑in _dlt_pipeline_state table in destination | External JSON via SLING_STATE env var (file/URI) | External JSON via SLING_STATE env var (file/URI) |
| Configuration | Automatic by default | Must set SLING_STATE to enable external state | Same as free |
| Visibility | Accessible via pipeline API & logs | Inspect the state JSON manually | Inspect & reset offsets via Sling Platform UI |
| Reset | dlt pipeline reset or delete state table schema | Delete or modify the JSON at SLING_STATE | Reset or rewind directly in the UI |
dlt uses a built‑in, code‑centric state table (_dlt_pipeline_state) for automatic tracking and easy resets.
Sling (Free & Pro) relies on an external JSON file via SLING_STATE with Pro adding a UI for inspecting and rewinding offsets.
SLING_STATE JSON file is available for state management in both versions, its use for incremental loading is a Sling Pro-only feature for file-to-database, API-to-database, and database-to-file pipelines. Only database-to-database incremental loading works in the free version.8. Failure Handling
| Feature | dlt | Sling |
|---|---|---|
| Automatic Recovery | Built‑in checkpointing via _dlt_pipeline_state, automatically resumes on rerun | Requires manual restart after state recovery |
| State Corruption Protection | Validates and version‑controls state blobs in _dlt_pipeline_state to prevent corruption | External JSON state can become invalid or lost if the file/URI is unavailable |
| Error Context | Surfaces full Python stack traces for precise debugging | Basic error messages |
| Retry Logic | Configurable retry policies in dlt.config.toml | Built‑in retries configurable via SLING_RETRIES env var |
| Late Data Handling | Native lag/window parameters on incremental sources to include delayed records | No native support—late or out‑of‑order records require manual SQL transforms |
| Graceful Degradation | Continues pipeline runs with schema evolution, skipping or adapting bad records | Fails fast on unexpected schema or data errors—no built‑in fallback |
dlt provides automated checkpoint recovery, built‑in state validation, rich error contexts, configurable retries, lag handling, and schema‑aware degradation.
Sling relies on manual restarts and external state files, offering basic retries and hard‑fast failures.
9. Community vs Commercial cut-offs
| Feature | dlt | Sling |
|---|---|---|
| Community Channels | Slack workspace & GitHub Discussions - 4500+ community members | GitHub Discussions only; |
| GitHub Stars | 4K+ | 617 |
| OSS Maintainers | dlthub team & community (122 contributors) | Single maintainer & community (15 contributors) |
| Monthly Downloads | 2M+ monthly downloads | Less than 100K monthly downloads |
| in OSS | Everything including advanced features | Sling CLI (core features) |
| Paywalled features | None | Advanced features in Sling Pro. |
| Hosted runtime offering | Future | Sling platform runtime |
dlt’s mission is to be the pythonic standard for data ingestion, offering full functionality in OSS and featuring a large community of users.
Sling is run by a one person team; support happens solely through GitHub Discussions, with a smaller contributor base and fewer downloads.
Final Take
Across our tests, dlt consistently led in the relevant points when building a pythonic data stack:
- For performance, dlt wins in all 3 categories: speed, CPU usage, and memory, with the PyArrow backend.
- For speed, dlt wins with ConnectorX backend which carries a disadvantage on memory management. Sling pro, the commercial version, is 30% slower than ConnectorX and requires 4x more CPU.
- For control, dlt wins, with memory management, hooks, chunking, parallelism. In Sling, these features are behind paywall.
- For cost, dlt wins with 3-4x less CPU needed for the same work than Sling and Sling pro
- dlt enables standardised ingestion - one tool for SQL, APIs, files, etc.
- For Pythonic data teams, dlt offers a native python solution
While Sling comes in second in the data engineering relevant categories, it is a solid tool that offers a good alternative for no-code, CLI first use cases with a low learning curve.
Already a dlt user?
Try dltHub free for 14 days, $30 in credits included.