on top of any data warehouse.
dltHub is an AI-native data engineering platform for teams of humans and agents. Your team and their agents generate and manage high-quality data at scale, on infrastructure we run for you.
Any engineer on your team can ship production data, with agents doing the work on infra we run. Every run is logged and auditable.
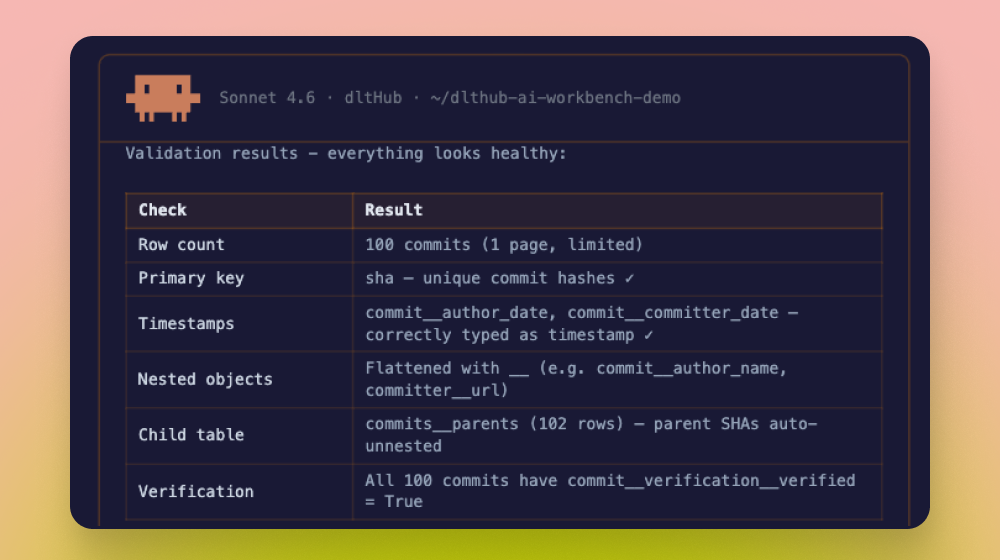
Paste this prompt into Claude, Codex, or Cursor. The agent does the rest.
Run uvx dlthub-start@latest to build my first pipeline and run it on dltHub
Your coding agent
Claude Code, Cursor or Codex
dlt Sources
 the managed infra layer
the managed infra layerdltHub is a composable data platform. Blueprints are its ready-made builds: each one dltHub assembled for a specific use case, end to end, from the sources you already use to a production dashboard or API.
Your coding agent
Claude Code, Cursor or Codex
the agentic layerdltHub AI harness
Agentic primitives to build, run and fix pipelines
dltHub context catalog
Lineage, schema, data quality, governance, run state
Pydantic Logfire
Arize
Langfuse
LangChain
the managed infra layerIngest and standardize traces into the OpenAI messages format as a training-ready dataset.
distil labs
Fine-tune a specialist model, served as a drop-in replacement via API to distil labs customers.
"What I didn't expect is how much it unblocks the team. A mid-level engineer can spin up a prototype, browse the raw data in dltHub's local DuckDB workspace, validate the SQL schema - all without pulling in a senior. That loop of prototype, inspect, fix, re-run - that's the real unlock."

Marcello Victorino
Staff Data Engineer, Tasman Analytics
Marcello Victorino
Staff Data Engineer, Tasman Analytics
Build a pipeline that loads CRM contacts and deals into my warehouse using dlt
Not autocomplete, not a chatbot on a dashboard. The harness is the skills, commands, rules, and MCP tools that walk Claude Code, Codex, or Cursor through building a pipeline and then keeping it running in production: scheduled runs, schema changes, failures. Maintained by dltHub and wired to the infrastructure your pipelines run on, so your data team ships without a platform team.
What your agent reaches for, step by step, from first prompt through the pipelines it keeps running.
The guided entry point. Names a use case, checks the workspace, and hands off to the right toolkit in a few prompts.
Opus 5.0 · Quick Start · ~/pipelines
Take me through the full workflow with the GitHub API
The guided entry point. Names a use case, checks the workspace, and hands off to the right toolkit in a few prompts.
Opus 5.0 · Quick Start · ~/pipelines
Take me through the full workflow with the GitHub API
Agent-led migration off your legacy vendor, 90% faster.
A months-long migration is what keeps teams tied to legacy tools they have outgrown, and what vendors count on to keep you locked in. We make it the easy part. Our engineers, armed with internal AI tooling, rebuild your Fivetran, Airbyte, and custom Python pipelines as clean dltHub code. We hand over pipelines running in production and coach your team on AI-forward data engineering.

In January 2025, the dlt community created 2,400 pipelines, almost entirely by hand. By January 2026, that number had grown to 81,000. The shift is not just the 34x year-over-year volume increase: agents now build roughly 10x more pipelines per month than human developers, accounting for ~91% of all new pipelines. The same inflection seen with databases such as Neon or Supabase is happening with data pipelines, only faster.
Use dlt as your open-source ingestion foundation and move to dltHub when you need managed runtime, observability, and governed collaboration at scale.
Apache 2.0
pip install dlt
The current machine learning revolution has been enabled by the Cambrian explosion of Python open-source tools that have become so accessible that a wide range of practitioners can use them. As a simple-to-use Python library, dlt is the first tool that this new wave of people can use. By leveraging this library, we can extend the machine learning revolution into enterprise data.

Julien Chaumond
CTO/Co-Founder at Hugging Face

Python and machine learning under security constraints are key to our success. We found that our cloud ETL provider could not meet our needs. dlt is a lightweight yet powerful open source tool we can run together with Snowflake. Our event streaming and batch data loading performs at scale and low cost. Now anyone who knows Python can self-serve to fulfil their data needs.

Maximilian Eber
CPTO & Co-Founder at Taktile
I am building our internal skills usage leaderboard so we can see how people are using AI and spread what's working. It started as a hacked-together GitHub Workflow calling the Databricks API and dumping output to JSON. dltHub turns this into a cohesive process without messy scripts to dedupe queries or wrangle intermediate tables. And the best part is anyone on the team can use agents to easily contribute.

Nate Sesti
Co-Founder & CTO at Continue
Free, self-paced course. From first prompt to production deployment.
dltHub's agentic workflows come with a REST API toolkit that taps directly into dltHub Context - a hub of deeply researched, enriched context on REST APIs across SaaS sources, databases, and destinations. Your agent pulls exactly what it needs to code any dlt pipeline, in minutes.
We already cover more than 10,100 sources, with a clear path to hundreds of thousands. From prompt to pipeline to live reports in a notebook - all in one agentic flow, with outputs tailored to data users.

Tools like Claude skills or Replit are great for writing and running code. But they are not built for data engineering workflows end to end.
dltHub gives your team complete agentic workflows that cover every phase: coding, running, deploying, and debugging pipelines, on infrastructure you control. Not just a skill, not just an editor, but a guided workflow from first line to production.
dlt is the perfect match between standardization and customization. You get the automation that matters: schema inference, incremental state, normalization, and loading, while keeping the full flexibility and portability of plain Python.
And with agentic dltHub workflows, your team can code, run, deploy, and debug pipelines faster, with the reliability you can trust at every step.
dltHub is the managed platform for deploying and operating data pipelines built with dlt. It provides a runtime, observability, data quality checks, and collaboration features so teams can go from development to production with one command.
dlt (data load tool) is an open-source Python library for building data pipelines. It lets you write any connector, run anywhere, and requires no backend. dlt is Apache 2.0 licensed and always free to use.