Why a simple task speaks volumes
Ajay Moorjani turned a deceptively simple JSON to Snowflake task into a rock solid pipeline using dlt, dbt, and Airflow, built in less than a coffee break.
 Aman Gupta,
Aman Gupta,
Data Engineer
"Just load some JSONL from S3 into Snowflake."
This is the kind of sentence that should come with a jump scare. It sounds harmless, but it hides a hundred ways to wreck your weekend.
Do you:
- Bash together a quick script and pray it survives prod?
- Or pause and ask, "Will this detonate when someone renames a column?"
Spoiler: It should be option B. But most folks go with A.
Before you slam that COPY INTO like it owes you money, ask:
- Is this pipeline idempotent?
- Can it handle schema drift?
- Will you cry when the bill arrives?
- How do I recover quickly when something breaks?
These aren’t "just" small tasks. They’re best practices that ensure your work doesn’t trap you in house-of-cards maintenance work.
✅ Quiet signs of strong engineering
Good engineers don’t show off with buzzwords. They prep for reality: retries, helpful logs, and simple pipelines that keep running quietly.

🚩 Red flags
The worst bugs aren’t loud. They’re invisible until they snowball.
Everything’s hardcoded. Rename one file and the whole thing collapses. Classic ‘works on my machine’ energy.
Ajay’s solution dodged all of this. Just a few lines of Python, but it had the fingerprints of someone who’s seen things.
Why it matters
Small tasks are the system. Do them right, and things quietly work. Do them wrong, and chaos piles up.
So here's how Ajay took one of those deceptively simple asks and nailed it.
Turning raw logs into queryable tables
The setup: a partner was dropping nightly JSON logs into S3. These needed to be in Snowflake by the time everyone grabbed their coffee. Not massive volume, but plenty of chances to mess up.
Ajay didn’t go the hacky script route. He built a clean, production-ready pipeline in 30 mins.
🧐 The Problem
This was a classic micro pipeline: small data volumes, simple formats, and no UI requirements. Spinning up a full ELT platform would’ve been overkill. But skipping best practices would’ve meant future pain.
The Solution
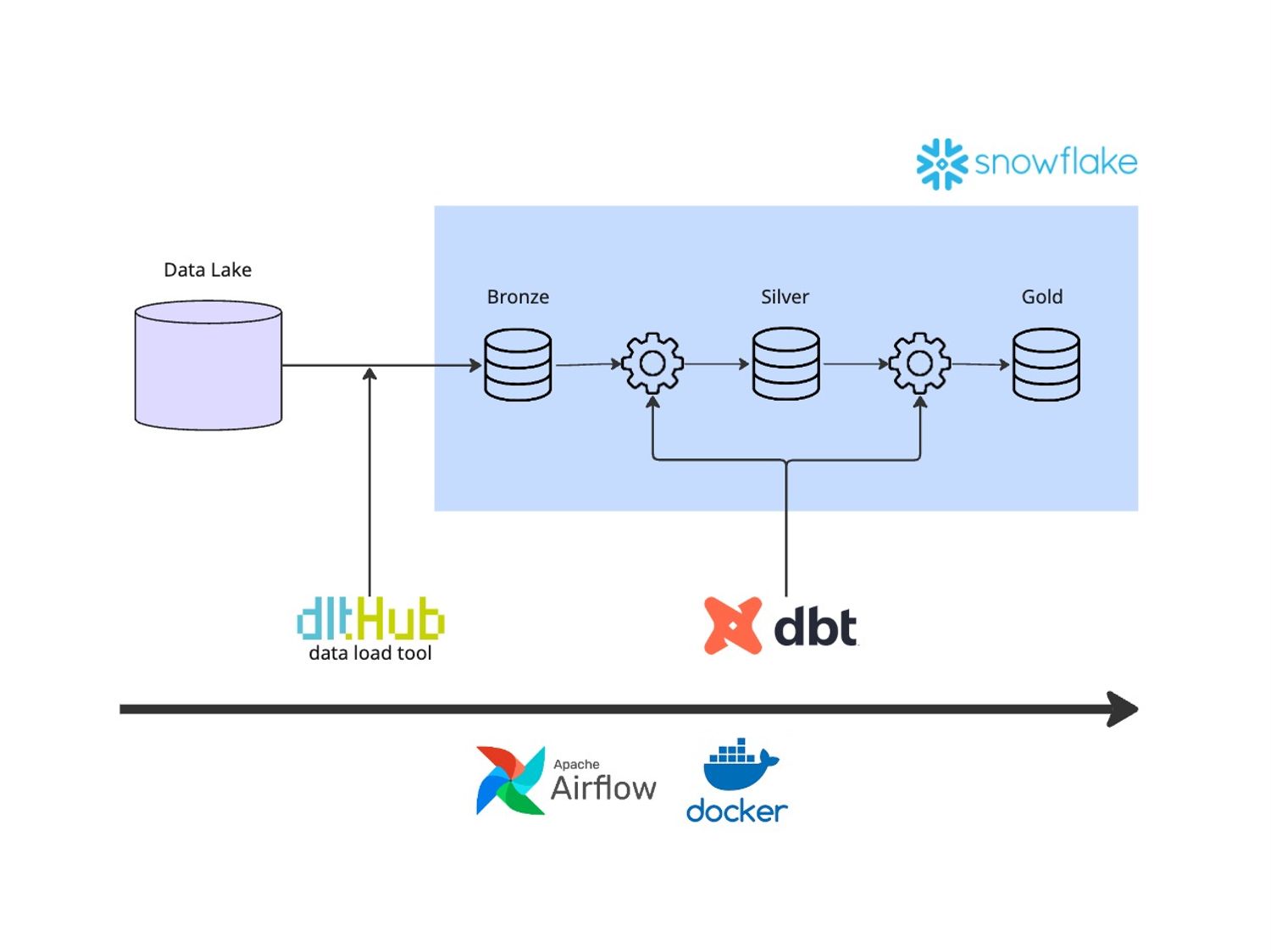
Ajay’s setup flows cleanly, step by step:
- A lightweight Airflow DAG kicks off daily, triggering a task.
- That task runs a dlt pipeline to stream new file batches directly into Snowflake.
- A dbt job then transforms the raw logs into structured models, Bronze, Silver, and Gold, using incremental builds.
- Unit and dbt tests validate each step to catch issues early.
What makes this pipeline well-engineered
Ajay’s pipeline is well-engineered not because it’s complex, but because it’s thoughtful.
- Each part does one job well - Airflow schedules, dlt ingests to Snowflake, and dbt transforms the data. Simple, clean, and modular.
- Resilient by design - Safe retries, idempotent loads, and incremental models mean you can re-run it without chaos.
- No unnecessary magic - He used tools already in place (like Airflow), avoided over-engineering, and let the defaults work for him.
- Actually tested - Unit and dbt tests catch issues before they spread.
It’s the kind of setup that just works and keeps working. Not flashy. Just solid.
TL;DR: Build like Ajay
Next time someone assigns you a “small” task, take a moment to think it through and make it boring, in the best possible way.
Check it out on Ajay's Github.
Want to build your own?
Start with these:
"Small tasks" aren't small when they run every day. Get them right, and everything else falls into place.