Migrate your SQL data pipeline from Airbyte to dlt
In this post, we explore how to migrate your SQL data pipeline from Airbyte to dlt, an open-source solution that offers greater control, speed, and cost-efficiency. If you're ready to take your data strategy to the next level, this guide will show you how to make the switch. Dive in and start your journey.
 Aman Gupta,
Aman Gupta,
Data Engineer
On this page
- Introduction
- Why migrate from Airbyte to dlt?
- Preparing for the migration
- Step 1: Disable the Airbyte pipeline
- Step 2: Create a new dlt Pipeline with incremental loading
- 2.1. Initialize the dlt Pipeline
- 2.2. Pipeline Setup Guide
- 2.3. Setup dlt pipeline
- Step 3: Running the Pipeline
- Staging layer: Why do we need it?
- Creating the unified views
- About Metadata
- Conclusion
- Call to action
Introduction
Most organisations have a "production" SQL database that contains most of the business or product usage data. Copying this SQL database to an analytical environment is often the starting point for a data stack.
When starting a data stack, we often pick whatever tools are available and offer the connectors we want. However, these tools often reach limitations later that we are unhappy with, from cost, to scaling limitations.
In this guide, we will explore how to migrate your SQL data pipeline from Airbyte to dlt. While we focus on MySQL in this example, a similar approach can be applied to other SQL databases.
Why migrate from Airbyte to dlt?
Airbyte offers a broad connector catalogue which makes it an easy way to get started building a data stack. However, there are many reasons why users prefer to move to dlt, such as:
- dlt is python native and can be developed with and tested easily, without having to go through any extra complexities. It can be deployed directly where you run the rest of your python code without the need for containers.
- dlt scales easily both on single hardwares, and on things like airflow workers.
- dlt is resilent with easy memory management, and customisable automations for self maintaining pipelines.
- dlt can be managed like the rest of your code, without having to create special things around orchestration, credentials etc.
- dlt pipelines can easily be customised with any extra logic.
- Standardisation: Once you begin building custom python pipelines, you might as well stick with one way of doing things to increase efficiency.
- Speed and scale: dlt is efficient to run and performance is within your control.
A small speed test:
dlt can leverage parallelism, but even without it dlt can be very fast by making use of technologies like Arrow and ConnectorX. See below how running dlt with various backends compares to a cloud version of Airbyte.
Dataset used: UNSW-NB15
Rows synced: 2.1 million
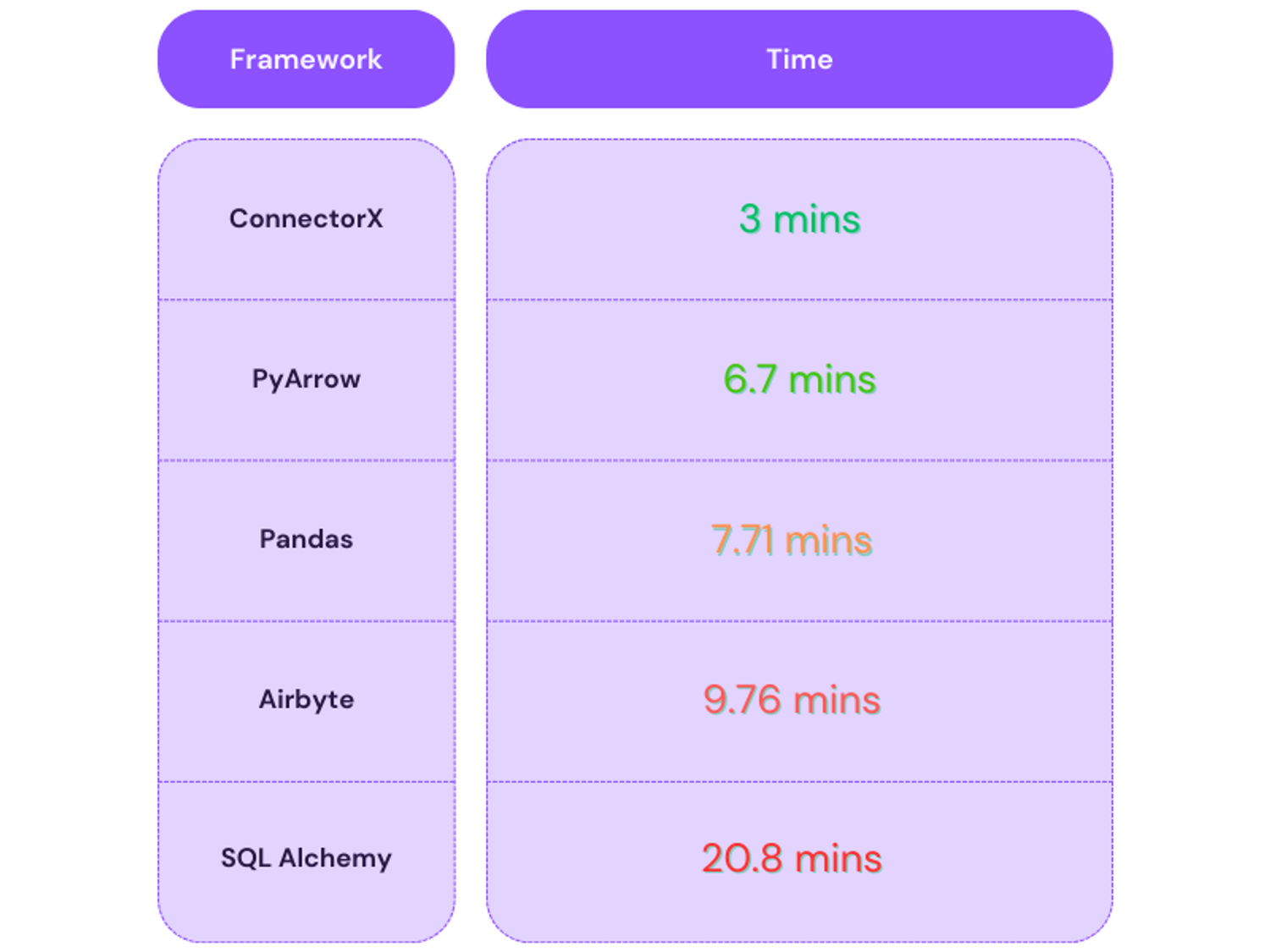
For any organization that wants to reduce its data ingestion costs and improve ingestion speed, open-source dlt seems to be a better choice.
Preparing for the migration
So you decided to migrate? In this tutorial we’ll be migrating a SQL to BigQuery pipeline from Airbyte to dlt , with the goal of having continuous data once we do the switch.
The steps we will follow:
1. Stop old pipeline, set up a new one
2. Merge the 2 data sets to avoid needing to back-fill historical data
If your database is small or if the copy is not incremental, you can just skip the merging of the 2 datasets and just load from scratch. If you get stuck on any of the steps, do not hesitate to ask for help in our Slack community.
If you have a larger migration to do, perhaps beyond the scope of SQL copy, and need professional support, consider to get in touch with our Solutions Engineering team.
Step 1: Disable the Airbyte pipeline
Let’s assume that you are using your already-built and running Airbyte pipeline. Our first step would be to disable the already running SQL pipeline as follows:

Steps to follow:
- Navigate to the "Connections" section on the left panel.
- Choose the MySQL connection used for transferring data.
- Click the disable button to stop data syncing from MySQL to BigQuery.
- Note the date and time that you pause the pipeline on, as it is to be used in configuring the
dltpipeline.
Let’s look at the “contacts” table created by Airbyte in BigQuery named “Airbyte_contacts”. Here’s the schema:
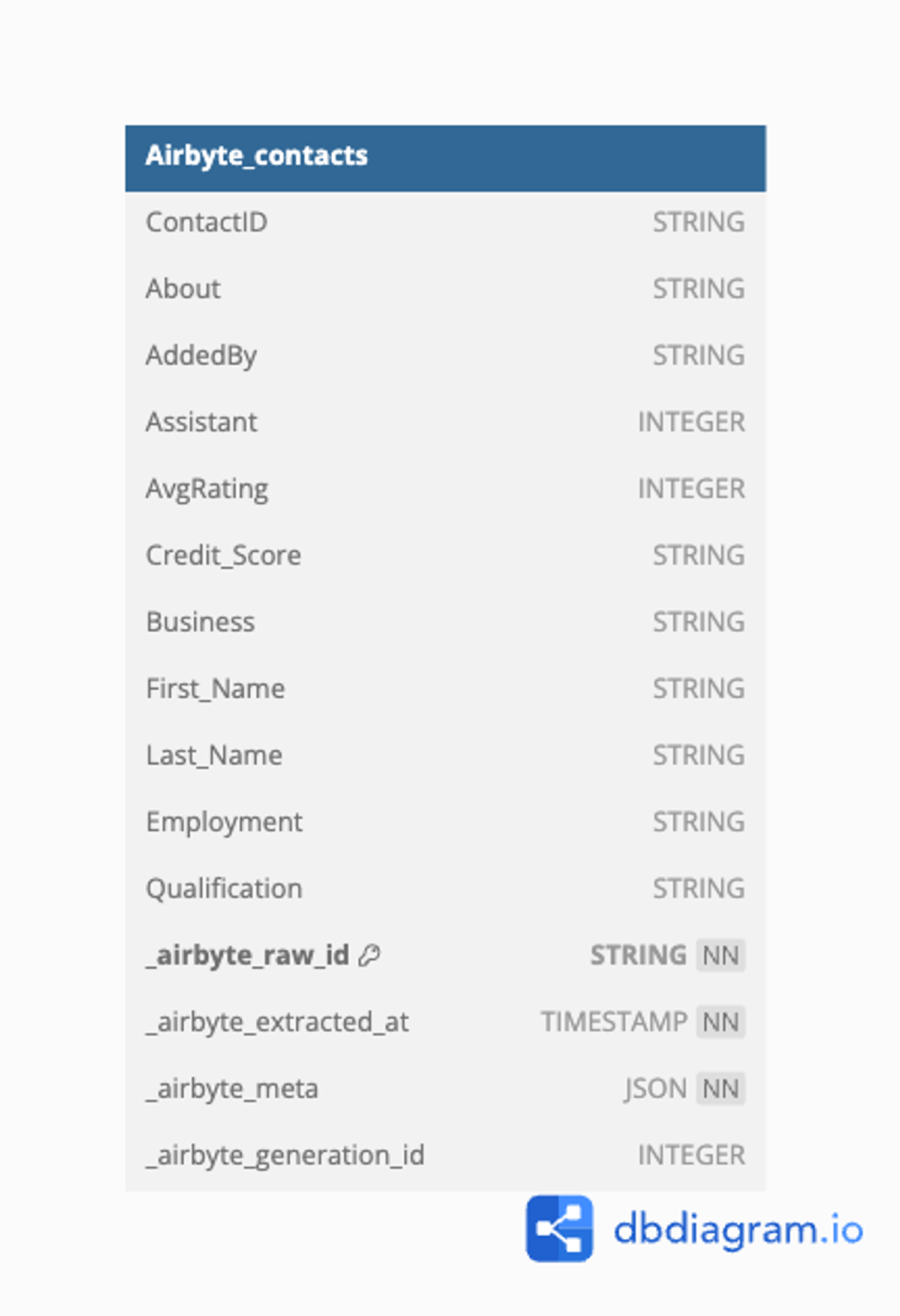
DB diagram: Airbyte_contacts.
Step 2: Create a new dlt Pipeline with incremental loading
With the Airbyte connector paused, any new data flowing into SQL post-migration cutoff needs to be captured. Here, dlt becomes our new vessel. And we create a pipeline to handle incremental loads, ensuring no new data is lost in transition.
Here are the steps:
2.1. Initialize the dlt Pipeline
To begin, initialize a dlt pipeline for SQL database. This involves setting up the pipeline with the desired source (SQL database) and destination (BigQuery, in this case).
dlt init sql_database bigqueryThis command creates a new directory with the necessary files and configurations.
2.2. Pipeline Setup Guide
To learn to set up the SQL database-BigQuery dlt pipeline, please read our verified source setup guide here.
2.3. Setup dlt pipeline
Next, we'll set up a pipeline to extract data from MySQL and load it into BigQuery. We'll configure this pipeline to load the data incrementally.
How to do incremental loading with dlt?
- Here is a walkthrough for SQL tables in our docs: Link to the new docs
- For more information about incremental loading, please refer to the official documentation here.
An example:
dlt enables you to do incremental loading. In this context, we need to give our pipeline a reference in time after which it should fetch the data from MySQL, so we’ll use the created column to fetch records created after the initial load date(which in our case is the Airbyte migration pause date).
dlt uses sources and resources to represent sources and their endpoints/tables. In the SQL pipeline, our source is the schema and the resource is a sql_table resource. We will specifically discuss how to load the "contact" table incrementally using the corresponding resource starting from an initial value (where we left off in 5tran). This will allow us to load data added after a specific date and time.
Here’s an example of a pipeline loading the “Contact” table incrementally.
def load_standalone_table_resource() -> None:
"""Load a few known tables with the standalone sql_table resource"""
pipeline = dlt.pipeline(
pipeline_name="mysql_database",
destination='bigquery',
dataset_name="dlt_contacts",
full_refresh=True,
)
# Load a table incrementally starting at a given date
contact = sql_table(
table="Contact",
incremental=dlt.sources.incremental(
"Created", initial_value=datetime(2024, 4, 1, 0, 0, 0))
),
)
# Run the pipeline
info = pipeline.run(contact)
# print the info
print(info)In this function, created is used as the incremental key to load only new records only the new records from Contact table.
To learn more about the adding incremental configuration to SQL resources, please refer to our documentation here.
Step 3: Running the Pipeline
Now, you can run the pipeline:
python sql_database_pipeline.pyHere’s the “Contact” table schema created by dlt named dlt_contacts:
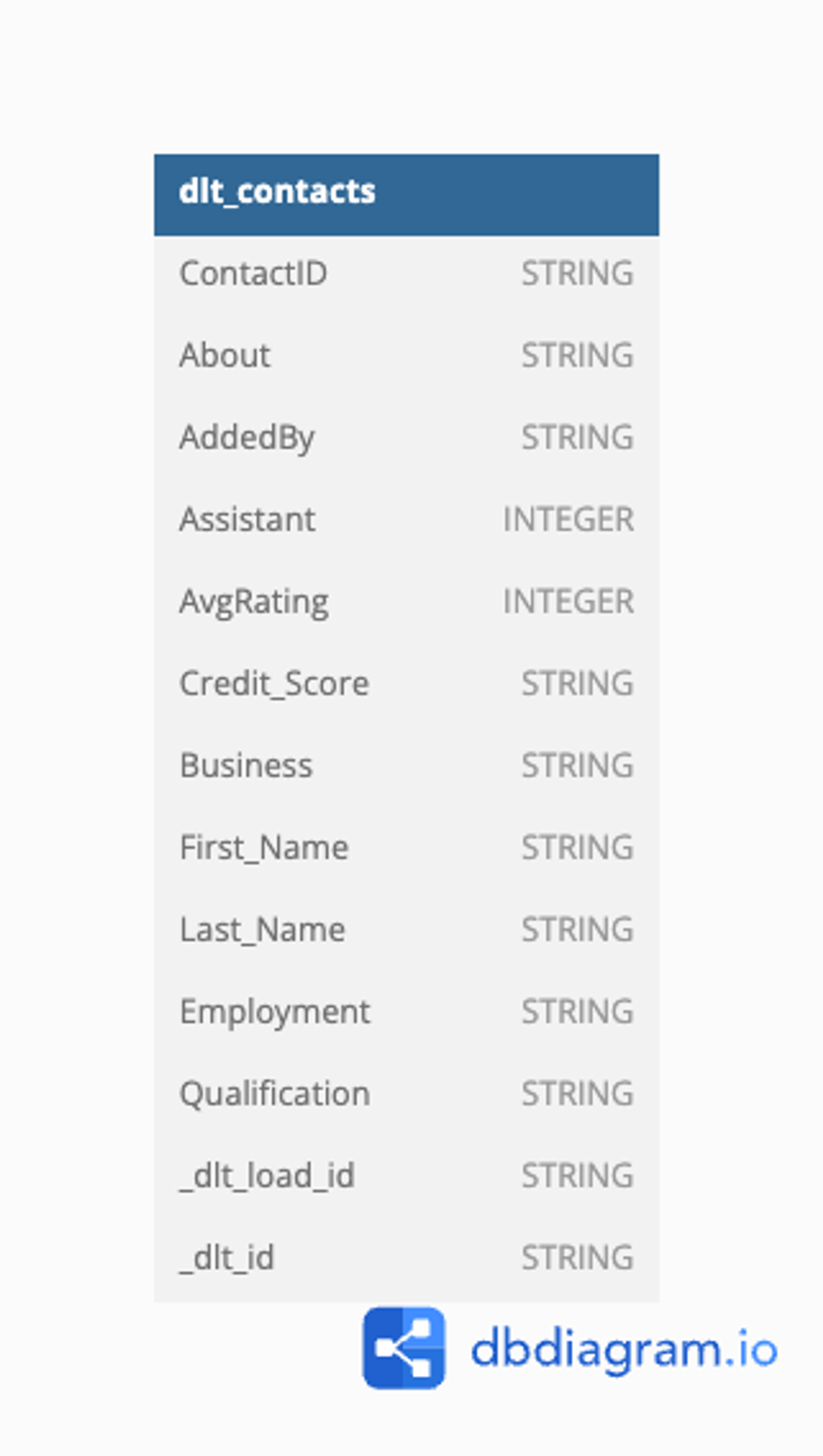
DB diagram: dlt_contacts.
Staging layer: Why do we need it?
To create a final view that includes both historical data from Airbyte and new data from dlt, we will treat the Airbyte and dlt tables as staging tables. Staging tables serve as intermediate storage areas where data can be cleaned, transformed, and validated before being loaded into the final destination. This approach facilitates the merging of datasets from both Airbyte and dlt, ensuring a cohesive and accurate final view.
Creating the unified views
Moving forward, we need to create a unified view where data from Airbyte and dlt converge into a single perspective. This merging process will be orchestrated using SQL views, ensuring an integration of both data sources.
Here's a snippet to illustrate the merging process:
CREATE OR REPLACE VIEW project-id.dataset.merged_contacts AS
WITH Airbyte_contacts as (
SELECT
ContactID as contact_id,
About as about,
AddedBy as added_by,
Assistant as assistant,
AvgRating as avg_rating,
Credit_Score as credir_score,
Business as business,
CommPreferred as comm_preferred,
reference,
Created as created,
CAST(NULL AS STRING) AS _dlt_load_id, -- dlt metadata
CAST(NULL AS STRING) AS _dlt_id, -- dlt metadata
_airbyte_raw_id, -- Airbyte metadata
_airbyte_extracted_at, -- Airbyte metadata
_airbyte_meta, -- Airbyte metadata
_airbyte_generation_id -- Airbyte metadata
FROM
dlt-dev-personal.Airbyte_contacts.Contact
WHERE created < '2024-07-01T12:30:02' -- datetime when Airbyte was paused
),
dlthub_contacts as (
SELECT
contact_id,
about,
added_by,
assistant,
avg_rating,
credit_score,
business,
comm_preferred,
reference,
created,
_dlt_load_id, -- dlt metadata
_dlt_id, -- dlt metadata
CAST(NULL as STRING) as _airbyte_raw_id, -- Airbyte metadata
CAST(NULL as TIMESTAMP) as _airbyte_extracted_at, -- Airbyte metadata
CAST(NULL as JSON) as _airbyte_meta, -- Airbyte metadata
CAST(NULL as INTEGER) as _airbyte_generation_id -- Airbyte metadata
FROM
dlt-dev-personal.mysql_data_20240725033145.contact
WHERE
created >= '2024-07-01T12:30:02' -- datetime when Airbyte was paused
)
SELECT * FROM Airbyte_contacts
UNION ALL
SELECT * FROM dlthub_contacts;This SQL snippet illustrates the merging of deals data from both Airbyte and dlt sources, ensuring a unified view.
dlt, careful attention must be given to naming conventions and data types. You can use the CAST function to change data types as needed, as demonstrated in the example above.Here is the schema for the merged view:
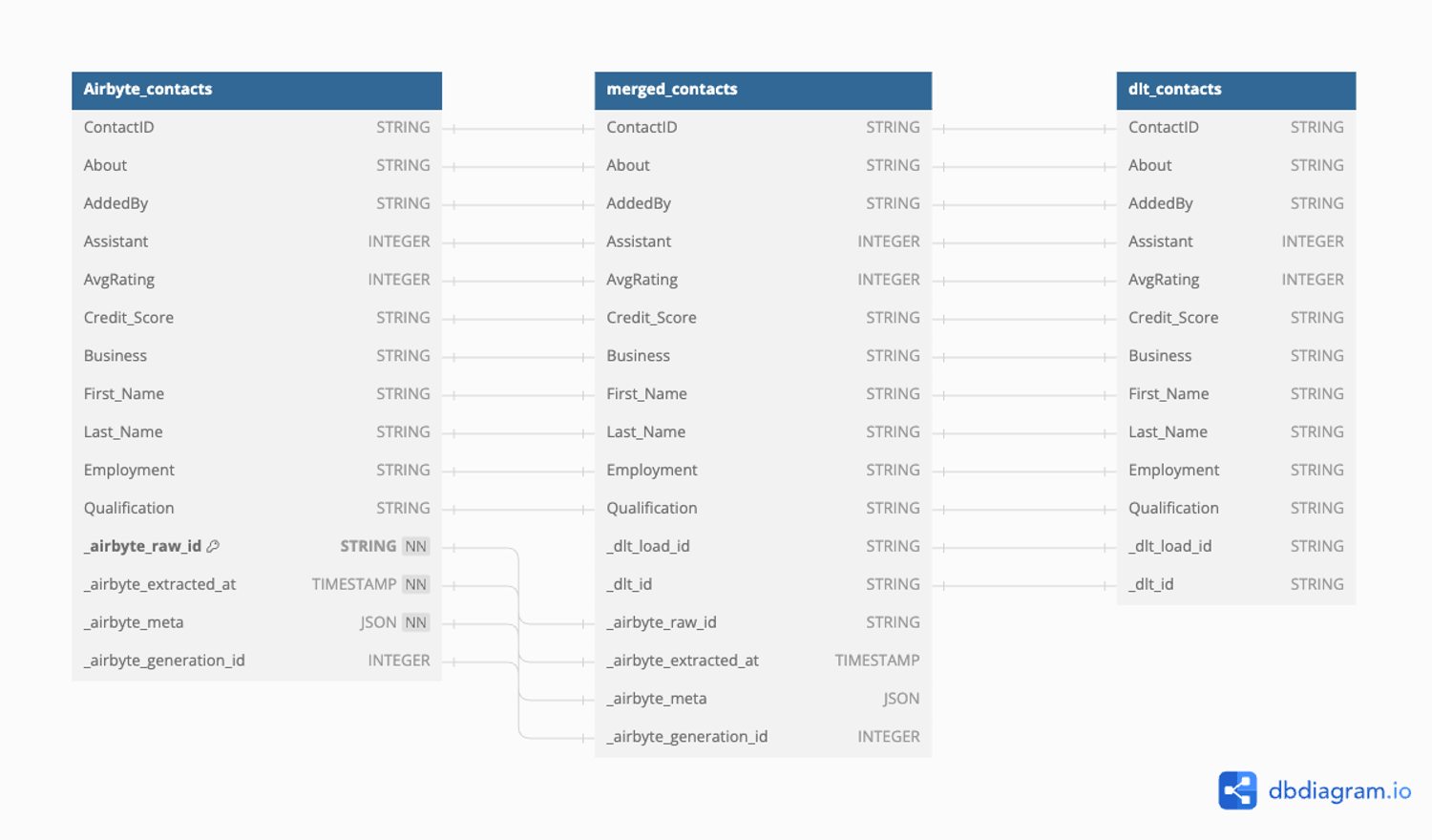
DB diagram: merged_view.
The methodology outlined in this guide ensures a smooth transition of your data pipeline from Airbyte to dlt .
About Metadata
The Airbyte metadata includes:
_airbyte_raw_id: primary key that uniquely identifies each record._airbyte_extracted_at: timestamp that marks the exact time when the record was extracted from the source system._airbyte_meta: JSON metadata that provides additional context about the record._airbyte_generation_id: integer that tracks the generation or version of the data, helping to manage and reconcile changes over time.
dlt assigns two key fields to each row: _dlt_id and _dlt_load_id.
- The
_dlt_iduniquely identifies each row, ensuring that every record can be traced back to its specific instance in the dataset. - The
_dlt_load_idis unique to each load operation, providing a way to track and audit data loads, especially in the context of incremental loading. This metadata is important for maintaining data integrity and understanding the history of data changes across different load operations.
To maintain the history of data dlt, employs an incremental loading strategy, typically SCD2 (Slowly Changing Dimension Type 2), to track changes in the data. This approach introduces additional columns such as _dlt_valid_from and _dlt_valid_to to understand the temporal validity of the data, indicating when a record was active in the source system. However, it's essential to note that this method applies only to new data being ingested by dlt.
Conclusion
In the article above, we explored the process of migrating the "contacts" table from a MySQL database to BigQuery. This methodology can be adapted for other databases like PostgreSQL, SQLite, Oracle, and Microsoft SQL Server, for migrating to various destinations supported by dlt. If you have a new destination in mind, you can either request it or contribute to the development yourself. The principles discussed remain consistent, regardless of the type of data. By following these straightforward steps, you can transition your data ingestion from Airbyte to dlt.
Call to action
Are you looking for help in moving from Airbyte to dlt? Our solutions engineering team offers an accelerated migration service including drop-in pipeline replacements and standardised dbt packages.
Get in touch with our Solutions Engineering team for fast, standardized migrations!