Incremental loading
Incremental loading is the act of loading only new or changed data and not old records that we already loaded. It enables low-latency and low cost data transfer.
The challenge of incremental pipelines is that if we do not keep track of the state of the load (i.e. which increments were loaded and which are to be loaded). Read more about state here.
Choosing a write disposition
The 3 write dispositions:
Full load: replaces the destination dataset with whatever the source produced on this run. To achieve this, use
write_disposition='replace'in your resources. Learn more in the full loading docsAppend: appends the new data to the destination. Use
write_disposition='append'.Merge: Merges new data to the destination using
merge_keyand/or deduplicates/upserts new data usingprimary_key. Usewrite_disposition='merge'.
Two simple questions determine the write disposition you use
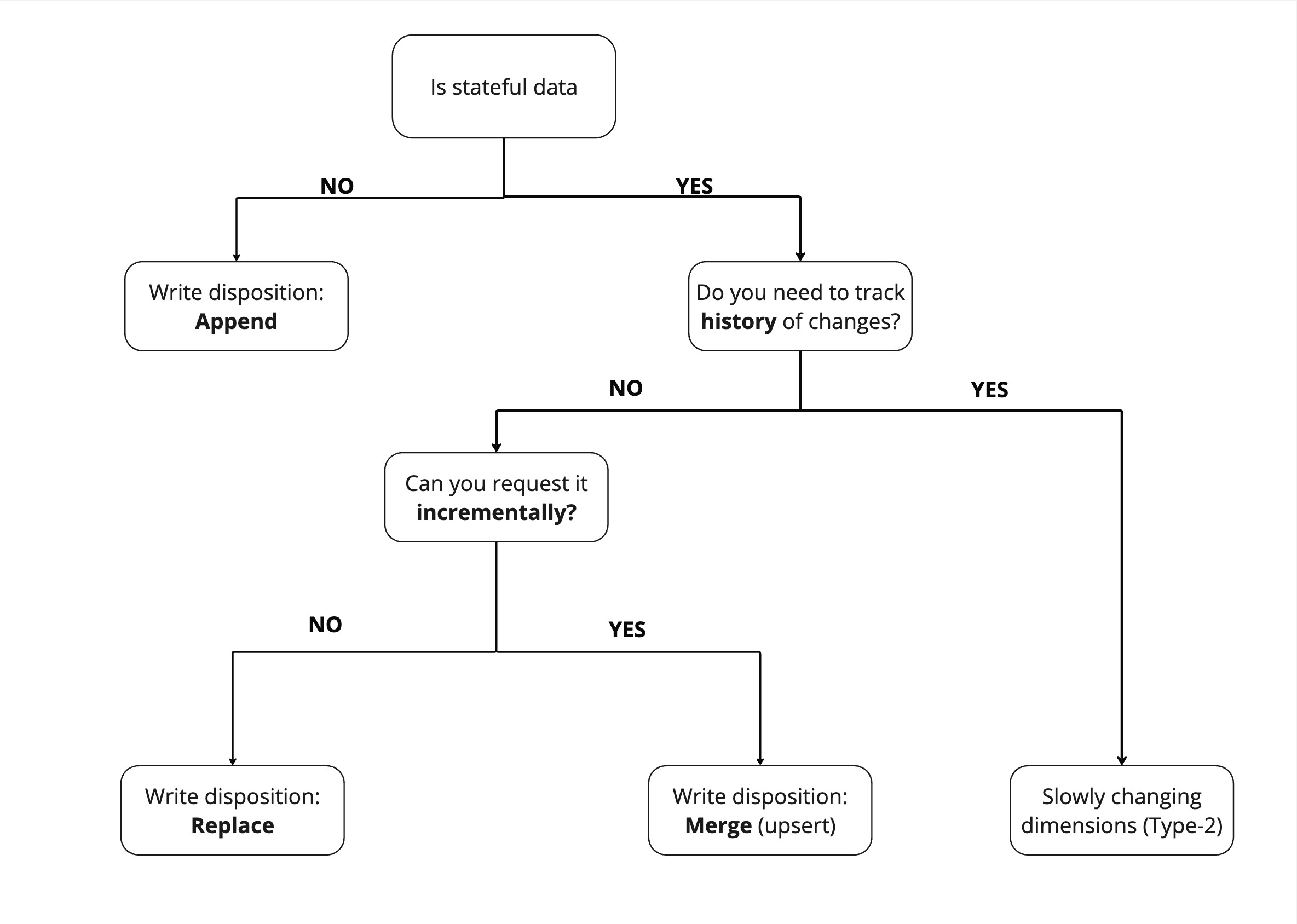
The "write disposition" you choose depends on the data set and how you can extract it.
To find the "write disposition" you should use, the first question you should ask yourself is "Is my data stateful or stateless"? Stateful data has a state that is subject to change - for example a user's profile Stateless data cannot change - for example, a recorded event, such as a page view.
Because stateless data does not need to be updated, we can just append it.
For stateful data, comes a second question - Can I extract it incrementally from the source? If yes, you should use slowly changing dimensions (Type-2), which allow you to maintain historical records of data changes over time.
If not, then we need to replace the entire data set. If however we can request the data incrementally such as "all users added or modified since yesterday" then we can simply apply changes to our existing dataset with the merge write disposition.
Merge incremental loading
The merge write disposition can be used with three different strategies:
1) delete-insert (default strategy)
2) scd2
3) upsert
delete-insert strategy
The default delete-insert strategy is used in two scenarios:
- You want to keep only one instance of certain record i.e. you receive updates of the
userstate from an API and want to keep just one record peruser_id. - You receive data in daily batches, and you want to make sure that you always keep just a single instance of a record for each batch even in case you load an old batch or load the current batch several times a day (i.e. to receive "live" updates).
The delete-insert strategy loads data to a staging dataset, deduplicates the staging data if a
primary_key is provided, deletes the data from the destination using merge_key and primary_key,
and then inserts the new records. All of this happens in a single atomic transaction for a parent and all
child tables.
Example below loads all the GitHub events and updates them in the destination using "id" as primary
key, making sure that only a single copy of event is present in github_repo_events table:
@dlt.resource(primary_key="id", write_disposition="merge")
def github_repo_events():
yield from _get_event_pages()
You can use compound primary keys:
@dlt.resource(primary_key=("id", "url"), write_disposition="merge")
def resource():
...
By default, primary_key deduplication is arbitrary. You can pass the dedup_sort column hint with a value of desc or asc to influence which record remains after deduplication. Using desc, the records sharing the same primary_key are sorted in descending order before deduplication, making sure the record with the highest value for the column with the dedup_sort hint remains. asc has the opposite behavior.
@dlt.resource(
primary_key="id",
write_disposition="merge",
columns={"created_at": {"dedup_sort": "desc"}} # select "latest" record
)
def resource():
...
Example below merges on a column batch_day that holds the day for which given record is valid.
Merge keys also can be compound:
@dlt.resource(merge_key="batch_day", write_disposition="merge")
def get_daily_batch(day):
yield _get_batch_from_bucket(day)
As with any other write disposition you can use it to load data ad hoc. Below we load issues with
top reactions for duckdb repo. The lists have, obviously, many overlapping issues, but we want to
keep just one instance of each.
p = dlt.pipeline(destination="bigquery", dataset_name="github")
issues = []
reactions = ["%2B1", "-1", "smile", "tada", "thinking_face", "heart", "rocket", "eyes"]
for reaction in reactions:
for page_no in range(1, 3):
page = requests.get(f"https://api.github.com/repos/{repo}/issues?state=all&sort=reactions-{reaction}&per_page=100&page={page_no}", headers=headers)
print(f"got page for {reaction} page {page_no}, requests left", page.headers["x-ratelimit-remaining"])
issues.extend(page.json())
p.run(issues, write_disposition="merge", primary_key="id", table_name="issues")
Example below dispatches GitHub events to several tables by event type, keeps one copy of each event by "id" and skips loading of past records using "last value" incremental. As you can see, all of this we can just declare in our resource.
@dlt.resource(primary_key="id", write_disposition="merge", table_name=lambda i: i['type'])
def github_repo_events(last_created_at = dlt.sources.incremental("created_at", "1970-01-01T00:00:00Z")):
"""A resource taking a stream of github events and dispatching them to tables named by event type. Deduplicates be 'id'. Loads incrementally by 'created_at' """
yield from _get_rest_pages("events")
If you use the merge write disposition, but do not specify merge or primary keys, merge will fallback to append.
The appended data will be inserted from a staging table in one transaction for most destinations in this case.
Delete records
The hard_delete column hint can be used to delete records from the destination dataset. The behavior of the delete mechanism depends on the data type of the column marked with the hint:
1) bool type: only True leads to a delete—None and False values are disregarded
2) other types: each not None value leads to a delete
Each record in the destination table with the same primary_key or merge_key as a record in the source dataset that's marked as a delete will be deleted.
Deletes are propagated to any child table that might exist. For each record that gets deleted in the root table, all corresponding records in the child table(s) will also be deleted. Records in parent and child tables are linked through the root key that is explained in the next section.
Example: with primary key and boolean delete column
@dlt.resource(
primary_key="id",
write_disposition="merge",
columns={"deleted_flag": {"hard_delete": True}}
)
def resource():
# this will insert a record (assuming a record with id = 1 does not yet exist)
yield {"id": 1, "val": "foo", "deleted_flag": False}
# this will update the record
yield {"id": 1, "val": "bar", "deleted_flag": None}
# this will delete the record
yield {"id": 1, "val": "foo", "deleted_flag": True}
# similarly, this would have also deleted the record
# only the key and the column marked with the "hard_delete" hint suffice to delete records
yield {"id": 1, "deleted_flag": True}
...
Example: with merge key and non-boolean delete column
@dlt.resource(
merge_key="id",
write_disposition="merge",
columns={"deleted_at_ts": {"hard_delete": True}})
def resource():
# this will insert two records
yield [
{"id": 1, "val": "foo", "deleted_at_ts": None},
{"id": 1, "val": "bar", "deleted_at_ts": None}
]
# this will delete two records
yield {"id": 1, "val": "foo", "deleted_at_ts": "2024-02-22T12:34:56Z"}
...
Example: with primary key and "dedup_sort" hint
@dlt.resource(
primary_key="id",
write_disposition="merge",
columns={"deleted_flag": {"hard_delete": True}, "lsn": {"dedup_sort": "desc"}})
def resource():
# this will insert one record (the one with lsn = 3)
yield [
{"id": 1, "val": "foo", "lsn": 1, "deleted_flag": None},
{"id": 1, "val": "baz", "lsn": 3, "deleted_flag": None},
{"id": 1, "val": "bar", "lsn": 2, "deleted_flag": True}
]
# this will insert nothing, because the "latest" record is a delete
yield [
{"id": 2, "val": "foo", "lsn": 1, "deleted_flag": False},
{"id": 2, "lsn": 2, "deleted_flag": True}
]
...
Indexing is important for doing lookups by column value, especially for merge writes, to ensure acceptable performance in some destinations.
Forcing root key propagation
Merge write disposition requires that the _dlt_id of top level table is propagated to child
tables. This concept is similar to foreign key which references a parent table, and we call it a
root key. Root key is automatically propagated for all tables that have merge write disposition
set. We do not enable it everywhere because it takes storage space. Nevertheless, is some cases you
may want to permanently enable root key propagation.
pipeline = dlt.pipeline(
pipeline_name='facebook_insights',
destination='duckdb',
dataset_name='facebook_insights_data',
dev_mode=True
)
fb_ads = facebook_ads_source()
# enable root key propagation on a source that is not a merge one by default.
# this is not required if you always use merge but below we start with replace
fb_ads.root_key = True
# load only disapproved ads
fb_ads.ads.bind(states=("DISAPPROVED", ))
info = pipeline.run(fb_ads.with_resources("ads"), write_disposition="replace")
# merge the paused ads. the disapproved ads stay there!
fb_ads = facebook_ads_source()
fb_ads.ads.bind(states=("PAUSED", ))
info = pipeline.run(fb_ads.with_resources("ads"), write_disposition="merge")
In example above we enforce the root key propagation with fb_ads.root_key = True. This ensures
that correct data is propagated on initial replace load so the future merge load can be
executed. You can achieve the same in the decorator @dlt.source(root_key=True).
scd2 strategy
dlt can create Slowly Changing Dimension Type 2 (SCD2) destination tables for dimension tables that change in the source. The resource is expected to provide a full extract of the source table each run. A row hash is stored in _dlt_id and used as surrogate key to identify source records that have been inserted, updated, or deleted. A NULL value is used by default to indicate an active record, but it's possible to use a configurable high timestamp (e.g. 9999-12-31 00:00:00.000000) instead.
The unique hint for _dlt_id in the root table is set to false when using scd2. This differs from default behavior. The reason is that the surrogate key stored in _dlt_id contains duplicates after an insert-delete-reinsert pattern:
- record with surrogate key X is inserted in a load at
t1 - record with surrogate key X is deleted in a later load at
t2 - record with surrogate key X is reinserted in an even later load at
t3
After this pattern, the scd2 table in the destination has two records for surrogate key X: one for validity window [t1, t2], and one for [t3, NULL]. A duplicate value exists in _dlt_id because both records have the same surrogate key.
Note that:
- the composite key
(_dlt_id, _dlt_valid_from)is unique _dlt_idremains unique for child tables—scd2does not affect this
Example: scd2 merge strategy
@dlt.resource(
write_disposition={"disposition": "merge", "strategy": "scd2"}
)
def dim_customer():
# initial load
yield [
{"customer_key": 1, "c1": "foo", "c2": 1},
{"customer_key": 2, "c1": "bar", "c2": 2}
]
pipeline.run(dim_customer()) # first run — 2024-04-09 18:27:53.734235
...
dim_customer destination table after first run—inserted two records present in initial load and added validity columns:
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | NULL | 1 | foo | 1 |
| 2024-04-09 18:27:53.734235 | NULL | 2 | bar | 2 |
...
def dim_customer():
# second load — record for customer_key 1 got updated
yield [
{"customer_key": 1, "c1": "foo_updated", "c2": 1},
{"customer_key": 2, "c1": "bar", "c2": 2}
]
pipeline.run(dim_customer()) # second run — 2024-04-09 22:13:07.943703
dim_customer destination table after second run—inserted new record for customer_key 1 and retired old record by updating _dlt_valid_to:
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | 2024-04-09 22:13:07.943703 | 1 | foo | 1 |
| 2024-04-09 18:27:53.734235 | NULL | 2 | bar | 2 |
| 2024-04-09 22:13:07.943703 | NULL | 1 | foo_updated | 1 |
...
def dim_customer():
# third load — record for customer_key 2 got deleted
yield [
{"customer_key": 1, "c1": "foo_updated", "c2": 1},
]
pipeline.run(dim_customer()) # third run — 2024-04-10 06:45:22.847403
dim_customer destination table after third run—retired deleted record by updating _dlt_valid_to:
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | 2024-04-09 22:13:07.943703 | 1 | foo | 1 |
| 2024-04-09 18:27:53.734235 | 2024-04-10 06:45:22.847403 | 2 | bar | 2 |
| 2024-04-09 22:13:07.943703 | NULL | 1 | foo_updated | 1 |
Example: configure validity column names
_dlt_valid_from and _dlt_valid_to are used by default as validity column names. Other names can be configured as follows:
@dlt.resource(
write_disposition={
"disposition": "merge",
"strategy": "scd2",
"validity_column_names": ["from", "to"], # will use "from" and "to" instead of default values
}
)
def dim_customer():
...
...
Example: configure active record timestamp
You can configure the literal used to indicate an active record with active_record_timestamp. The default literal NULL is used if active_record_timestamp is omitted or set to None. Provide a date value if you prefer to use a high timestamp instead.
@dlt.resource(
write_disposition={
"disposition": "merge",
"strategy": "scd2",
# accepts various types of date/datetime objects
"active_record_timestamp": "9999-12-31",
}
)
def dim_customer():
...
Example: configure boundary timestamp
You can configure the "boundary timestamp" used for record validity windows with boundary_timestamp. The provided date(time) value is used as "valid from" for new records and as "valid to" for retired records. The timestamp at which a load package is created is used if boundary_timestamp is omitted.
@dlt.resource(
write_disposition={
"disposition": "merge",
"strategy": "scd2",
# accepts various types of date/datetime objects
"boundary_timestamp": "2024-08-21T12:15:00+00:00",
}
)
def dim_customer():
...
Example: use your own row hash
By default, dlt generates a row hash based on all columns provided by the resource and stores it in _dlt_id. You can use your own hash instead by specifying row_version_column_name in the write_disposition dictionary. You might already have a column present in your resource that can naturally serve as row hash, in which case it's more efficient to use those pre-existing hash values than to generate new artificial ones. This option also allows you to use hashes based on a subset of columns, in case you want to ignore changes in some of the columns. When using your own hash, values for _dlt_id are randomly generated.
@dlt.resource(
write_disposition={
"disposition": "merge",
"strategy": "scd2",
"row_version_column_name": "row_hash", # the column "row_hash" should be provided by the resource
}
)
def dim_customer():
...
...
🧪 Use scd2 with Arrow Tables and Panda frames
dlt will not add row hash column to the tabular data automatically (we are working on it).
You need to do that yourself by adding a transform function to scd2 resource that computes row hashes (using pandas.util, should be fairly fast).
import dlt
from dlt.sources.helpers.transform import add_row_hash_to_table
scd2_r = dlt.resource(
arrow_table,
name="tabular",
write_disposition={
"disposition": "merge",
"strategy": "scd2",
"row_version_column_name": "row_hash",
},
).add_map(add_row_hash_to_table("row_hash"))
add_row_hash_to_table is the name of the transform function that will compute and create row_hash column that is declared as holding the hash by row_version_column_name.
You can modify existing resources that yield data in tabular form by calling apply_hints and passing scd2 config in write_disposition and then by
adding the transform with add_map.
Child tables
Child tables, if any, do not contain validity columns. Validity columns are only added to the root table. Validity column values for records in child tables can be obtained by joining the root table using _dlt_root_id.
Limitations
- You cannot use columns like
updated_ator integerversionof a record that are unique within aprimary_key(even if it is defined). Hash column must be unique for a root table. We are working to allowupdated_atstyle tracking - We do not detect changes in child tables (except new records) if row hash of the corresponding parent row does not change. Use
updated_ator similar column in the root table to stamp changes in nested data. merge_key(s)are (for now) ignored.
upsert strategy
The upsert merge strategy is currently supported for these destinations:
athenabigquerydatabricksmssqlpostgressnowflake- 🧪
filesytemwithdeltatable format (see limitations here)
The upsert merge strategy does primary-key based upserts:
- update record if key exists in target table
- insert record if key does not exist in target table
You can delete records with the hard_delete hint.
upsert versus delete-insert
Unlike the default delete-insert merge strategy, the upsert strategy:
- needs a
primary_key - expects this
primary_keyto be unique (dltdoes not deduplicate) - does not support
merge_key - uses
MERGEorUPDATEoperations to process updates
Example: upsert merge strategy
@dlt.resource(
write_disposition={"disposition": "merge", "strategy": "upsert"},
primary_key="my_primary_key"
)
def my_upsert_resource():
...
...
Incremental loading with a cursor field
In most of the REST APIs (and other data sources i.e. database tables) you can request new or updated data by passing a timestamp or id of the "last" record to a query. The API/database returns just the new/updated records from which you take maximum/minimum timestamp/id for the next load.
To do incremental loading this way, we need to
- figure which field is used to track changes (the so called cursor field) (e.g. “inserted_at”, "updated_at”, etc.);
- how to past the "last" (maximum/minimum) value of cursor field to an API to get just new / modified data (how we do this depends on the source API).
Once you've figured that out, dlt takes care of finding maximum/minimum cursor field values, removing
duplicates and managing the state with last values of cursor. Take a look at GitHub example below, where we
request recently created issues.
@dlt.resource(primary_key="id")
def repo_issues(
access_token,
repository,
updated_at = dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
# get issues since "updated_at" stored in state on previous run (or initial_value on first run)
for page in _get_issues_page(access_token, repository, since=updated_at.start_value):
yield page
# last_value is updated after every page
print(updated_at.last_value)
Here we add updated_at argument that will receive incremental state, initialized to
1970-01-01T00:00:00Z. It is configured to track updated_at field in issues yielded by
repo_issues resource. It will store the newest updated_at value in dlt
state and make it available in updated_at.start_value on next pipeline
run. This value is inserted in _get_issues_page function into request query param since to Github API
In essence, dlt.sources.incremental instance above
- updated_at.initial_value which is always equal to "1970-01-01T00:00:00Z" passed in constructor
- updated_at.start_value a maximum
updated_atvalue from the previous run or the initial_value on first run - updated_at.last_value a "real time"
updated_atvalue updated with each yielded item or page. before first yield it equals start_value - updated_at.end_value (here not used) marking end of backfill range
When paginating you probably need start_value which does not change during the execution of the resource, however most paginators will return a next page link which you should use.
Behind the scenes, dlt will deduplicate the results ie. in case the last issue is returned again
(updated_at filter is inclusive) and skip already loaded ones.
In the example below we
incrementally load the GitHub events, where API does not let us filter for the newest events - it
always returns all of them. Nevertheless, dlt will load only the new items, filtering out all the
duplicates and past issues.
# use naming function in table name to generate separate tables for each event
@dlt.resource(primary_key="id", table_name=lambda i: i['type']) # type: ignore
def repo_events(
last_created_at = dlt.sources.incremental("created_at", initial_value="1970-01-01T00:00:00Z", last_value_func=max), row_order="desc"
) -> Iterator[TDataItems]:
repos_path = "/repos/%s/%s/events" % (urllib.parse.quote(owner), urllib.parse.quote(name))
for page in _get_rest_pages(access_token, repos_path + "?per_page=100"):
yield page
We just yield all the events and dlt does the filtering (using id column declared as
primary_key).
Github returns events ordered from newest to oldest. So we declare the rows_order as descending to stop requesting more pages once the incremental value is out of range. We stop requesting more data from the API after finding the first event with created_at earlier than initial_value.
dlt.sources.incremental is implemented as a filter function that is executed after all other transforms
you add with add_map / add_filter. This means that you can manipulate the data item before incremental filter sees it. For example:
- you can create surrogate primary key from other columns
- you can modify cursor value or create a new field composed from other fields
- dump Pydantic models to Python dicts to allow incremental to find custost values
Data validation with Pydantic happens before incremental filtering.
max, min or custom last_value_func
dlt.sources.incremental allows to choose a function that orders (compares) cursor values to current last_value.
- The default function is built-in
maxwhich returns bigger value of the two - Another built-in
minreturns smaller value.
You can pass your custom function as well. This lets you define
last_value on complex types i.e. dictionaries and store indexes of last values, not just simple
types. The last_value argument is a JSON Path
and lets you select nested and complex data (including the whole data item when $ is used).
Example below creates last value which is a dictionary holding a max created_at value for each
created table name:
def by_event_type(event):
last_value = None
if len(event) == 1:
item, = event
else:
item, last_value = event
if last_value is None:
last_value = {}
else:
last_value = dict(last_value)
item_type = item["type"]
last_value[item_type] = max(item["created_at"], last_value.get(item_type, "1970-01-01T00:00:00Z"))
return last_value
@dlt.resource(primary_key="id", table_name=lambda i: i['type'])
def get_events(last_created_at = dlt.sources.incremental("$", last_value_func=by_event_type)):
with open("tests/normalize/cases/github.events.load_page_1_duck.json", "r", encoding="utf-8") as f:
yield json.load(f)
Using last_value_func for lookback
The example below uses the last_value_func to load data from the past month.
def lookback(event):
last_value = None
if len(event) == 1:
item, = event
else:
item, last_value = event
if last_value is None:
last_value = {}
else:
last_value = dict(last_value)
last_value["created_at"] = pendulum.from_timestamp(item["created_at"]).subtract(months=1)
return last_value
@dlt.resource(primary_key="id")
def get_events(last_created_at = dlt.sources.incremental("created_at", last_value_func=lookback)):
with open("tests/normalize/cases/github.events.load_page_1_duck.json", "r", encoding="utf-8") as f:
yield json.load(f)
Using end_value for backfill
You can specify both initial and end dates when defining incremental loading. Let's go back to our Github example:
@dlt.resource(primary_key="id")
def repo_issues(
access_token,
repository,
created_at = dlt.sources.incremental("created_at", initial_value="1970-01-01T00:00:00Z", end_value="2022-07-01T00:00:00Z")
):
# get issues from created from last "created_at" value
for page in _get_issues_page(access_token, repository, since=created_at.start_value, until=created_at.end_value):
yield page
Above we use initial_value and end_value arguments of the incremental to define the range of issues that we want to retrieve
and pass this range to the Github API (since and until). As in the examples above, dlt will make sure that only the issues from
defined range are returned.
Please note that when end_date is specified, dlt will not modify the existing incremental state. The backfill is stateless and:
- You can run backfill and incremental load in parallel (ie. in Airflow DAG) in a single pipeline.
- You can partition your backfill into several smaller chunks and run them in parallel as well.
To define specific ranges to load, you can simply override the incremental argument in the resource, for example:
july_issues = repo_issues(
created_at=dlt.sources.incremental(
initial_value='2022-07-01T00:00:00Z', end_value='2022-08-01T00:00:00Z'
)
)
august_issues = repo_issues(
created_at=dlt.sources.incremental(
initial_value='2022-08-01T00:00:00Z', end_value='2022-09-01T00:00:00Z'
)
)
...
Note that dlt's incremental filtering considers the ranges half closed. initial_value is inclusive, end_value is exclusive, so chaining ranges like above works without overlaps.
Declare row order to not request unnecessary data
With row_order argument set, dlt will stop getting data from the data source (ie. Github API) if it detect that values of cursor field are out of range of start and end values.
In particular:
dltstops processing when the resource yields any item with an equal or greater cursor value than theend_valueandrow_orderis set to asc. (end_valueis not included)dltstops processing when the resource yields any item with a lower cursor value than thelast_valueandrow_orderis set to desc. (last_valueis included)
"higher" and "lower" here refers to when the default last_value_func is used (max()),
when using min() "higher" and "lower" are inverted.
If you use row_order, make sure that the data source returns ordered records (ascending / descending) on the cursor field,
e.g. if an API returns results both higher and lower
than the given end_value in no particular order, data reading stops and you'll miss the data items that were out of order.
Row order is the most useful when:
- The data source does not offer start/end filtering of results (e.g. there is no
start_time/end_timequery parameter or similar) - The source returns results ordered by the cursor field
The github events example is exactly such case. The results are ordered on cursor value descending but there's no way to tell API to limit returned items to those created before certain date. Without the row_order setting, we'd be getting all events, each time we extract the github_events resource.
In the same fashion the row_order can be used to optimize backfill so we don't continue
making unnecessary API requests after the end of range is reached. For example:
@dlt.resource(primary_key="id")
def tickets(
zendesk_client,
updated_at=dlt.sources.incremental(
"updated_at",
initial_value="2023-01-01T00:00:00Z",
end_value="2023-02-01T00:00:00Z",
row_order="asc"
),
):
for page in zendesk_client.get_pages(
"/api/v2/incremental/tickets", "tickets", start_time=updated_at.start_value
):
yield page
In this example we're loading tickets from Zendesk. The Zendesk API yields items paginated and ordered by oldest to newest,
but only offers a start_time parameter for filtering so we cannot tell it to
stop getting data at end_value. Instead we set row_order to asc and dlt wil stop
getting more pages from API after first page with cursor value updated_at is found older
than end_value.
In rare cases when you use Incremental with a transformer, dlt will not be able to automatically close
generator associated with a row that is out of range. You can still use still call can_close() method on
incremental and exit yield loop when true.
The dlt.sources.incremental instance provides start_out_of_range and end_out_of_range
attributes which are set when the resource yields an element with a higher/lower cursor value than the
initial or end values. If you do not want dlt to stop processing automatically and instead to handle such events yourself, do not specify row_order:
@dlt.transformer(primary_key="id")
def tickets(
zendesk_client,
updated_at=dlt.sources.incremental(
"updated_at",
initial_value="2023-01-01T00:00:00Z",
end_value="2023-02-01T00:00:00Z",
row_order="asc"
),
):
for page in zendesk_client.get_pages(
"/api/v2/incremental/tickets", "tickets", start_time=updated_at.start_value
):
yield page
# Stop loading when we reach the end value
if updated_at.end_out_of_range:
return
Deduplicate overlapping ranges with primary key
Incremental does not deduplicate datasets like merge write disposition does. It however
makes sure than when another portion of data is extracted, records that were previously loaded won't be
included again. dlt assumes that you load a range of data, where the lower bound is inclusive (ie. greater than equal).
This makes sure that you never lose any data but will also re-acquire some rows.
For example: you have a database table with an cursor field on updated_at which has a day resolution, then there's a high
chance that after you extract data on a given day, still more records will be added. When you extract on the next day, you
should reacquire data from the last day to make sure all records are present, this will however create overlap with data
from previous extract.
By default, content hash (a hash of json representation of a row) will be used to deduplicate.
This may be slow sodlt.sources.incremental will inherit the primary key that is set on the resource.
You can optionally set a primary_key that is used exclusively to
deduplicate and which does not become a table hint. The same setting lets you disable the
deduplication altogether when empty tuple is passed. Below we pass primary_key directly to
incremental to disable deduplication. That overrides delta primary_key set in the resource:
@dlt.resource(primary_key="delta")
# disable the unique value check by passing () as primary key to incremental
def some_data(last_timestamp=dlt.sources.incremental("item.ts", primary_key=())):
for i in range(-10, 10):
yield {"delta": i, "item": {"ts": pendulum.now().timestamp()}}
Using dlt.sources.incremental with dynamically created resources
When resources are created dynamically it is possible to
use dlt.sources.incremental definition as well.
@dlt.source
def stripe():
# declare a generator function
def get_resource(
endpoint: Endpoints,
created: dlt.sources.incremental=dlt.sources.incremental("created")
):
...
yield data
# create resources for several endpoints on a single decorator function
for endpoint in endpoints:
yield dlt.resource(
get_resource,
name=endpoint.value,
write_disposition="merge",
primary_key="id"
)(endpoint)
Please note that in the example above, get_resource is passed as a function to dlt.resource to
which we bind the endpoint: dlt.resource(...)(endpoint).
The typical mistake is to pass a generator (not a function) as below:
yield dlt.resource(get_resource(endpoint), name=endpoint.value, write_disposition="merge", primary_key="id").
Here we call get_resource(endpoint) and that creates un-evaluated generator on which resource
is created. That prevents dlt from controlling the created argument during runtime and will
result in IncrementalUnboundError exception.
Using Airflow schedule for backfill and incremental loading
When running in Airflow task, you can opt-in your resource to get the initial_value/start_value and end_value from Airflow schedule associated with your DAG. Let's assume that Zendesk tickets resource contains a year of data with thousands of tickets. We want to backfill the last year of data week by week and then continue incremental loading daily.
@dlt.resource(primary_key="id")
def tickets(
zendesk_client,
updated_at=dlt.sources.incremental[int](
"updated_at",
allow_external_schedulers=True
),
):
for page in zendesk_client.get_pages(
"/api/v2/incremental/tickets", "tickets", start_time=updated_at.start_value
):
yield page
We opt-in to Airflow scheduler by setting allow_external_schedulers to True:
- When running on Airflow, the start and end values are controlled by Airflow and
dltstate is not used. - In all other environments, the
incrementalbehaves as usual, maintainingdltstate.
Let's generate a deployment with dlt deploy zendesk_pipeline.py airflow-composer and customize the dag:
@dag(
schedule_interval='@weekly',
start_date=pendulum.datetime(2023, 2, 1),
end_date=pendulum.datetime(2023, 8, 1),
catchup=True,
max_active_runs=1,
default_args=default_task_args
)
def zendesk_backfill_bigquery():
tasks = PipelineTasksGroup("zendesk_support_backfill", use_data_folder=False, wipe_local_data=True)
# import zendesk like in the demo script
from zendesk import zendesk_support
pipeline = dlt.pipeline(
pipeline_name="zendesk_support_backfill",
dataset_name="zendesk_support_data",
destination='bigquery',
)
# select only incremental endpoints in support api
data = zendesk_support().with_resources("tickets", "ticket_events", "ticket_metric_events")
# create the source, the "serialize" decompose option will converts dlt resources into Airflow tasks. use "none" to disable it
tasks.add_run(pipeline, data, decompose="serialize", trigger_rule="all_done", retries=0, provide_context=True)
zendesk_backfill_bigquery()
What got customized:
- We use weekly schedule, and want to get the data from February 2023 (
start_date) until end of July ('end_date'). - We make Airflow to generate all weekly runs (
catchupis True). - We create
zendesk_supportresources where we select only the incremental resources we want to backfill.
When you enable the DAG in Airflow, it will generate several runs and start executing them, starting in February and ending in August. Your resource will receive
subsequent weekly intervals starting with 2023-02-12, 00:00:00 UTC to 2023-02-19, 00:00:00 UTC.
You can repurpose the DAG above to start loading new data incrementally after (or during) the backfill:
@dag(
schedule_interval='@daily',
start_date=pendulum.datetime(2023, 2, 1),
catchup=False,
max_active_runs=1,
default_args=default_task_args
)
def zendesk_new_bigquery():
tasks = PipelineTasksGroup("zendesk_support_new", use_data_folder=False, wipe_local_data=True)
# import your source from pipeline script
from zendesk import zendesk_support
pipeline = dlt.pipeline(
pipeline_name="zendesk_support_new",
dataset_name="zendesk_support_data",
destination='bigquery',
)
tasks.add_run(pipeline, zendesk_support(), decompose="serialize", trigger_rule="all_done", retries=0, provide_context=True)
Above, we switch to daily schedule and disable catchup and end date. We also load all the support resources to the same dataset as backfill (zendesk_support_data).
If you want to run this DAG parallel with the backfill DAG, change the pipeline name ie. to zendesk_support_new as above.
Under the hood
Before dlt starts executing incremental resources, it looks for data_interval_start and data_interval_end Airflow task context variables. Those got mapped to initial_value and end_value of the
Incremental class:
dltis smart enough to convert Airflow datetime to iso strings or unix timestamps if your resource is using them. In our example we instantiateupdated_at=dlt.sources.incremental[int], where we declare the last value type to be int.dltcan also infer type if you provideinitial_valueargument.- If
data_interval_endis in the future or is None,dltsets theend_valueto now. - If
data_interval_start==data_interval_endwe have a manually triggered DAG run. In that casedata_interval_endwill also be set to now.
Manual runs
You can run DAGs manually but you must remember to specify the Airflow logical date of the run in the past (use Run with config option). For such run dlt will load all data from that past date until now.
If you do not specify the past date, a run with a range (now, now) will happen yielding no data.
Reading incremental loading parameters from configuration
Consider the example below for reading incremental loading parameters from "config.toml". We create a generate_incremental_records resource that yields "id", "idAfter", and "name". This resource retrieves cursor_path and initial_value from "config.toml".
In "config.toml", define the
cursor_pathandinitial_valueas:# Configuration snippet for an incremental resource
[pipeline_with_incremental.sources.id_after]
cursor_path = "idAfter"
initial_value = 10cursor_pathis assigned the value "idAfter" with an initial value of 10.Here's how the
generate_incremental_recordsresource usescursor_pathdefined in "config.toml":@dlt.resource(table_name="incremental_records")
def generate_incremental_records(id_after: dlt.sources.incremental = dlt.config.value):
for i in range(150):
yield {"id": i, "idAfter": i, "name": "name-" + str(i)}
pipeline = dlt.pipeline(
pipeline_name="pipeline_with_incremental",
destination="duckdb",
)
pipeline.run(generate_incremental_records)id_afterincrementally stores the latestcursor_pathvalue for future pipeline runs.
Loading NULL values in the incremental cursor field
When loading incrementally with a cursor field, each row is expected to contain a value at the cursor field that is not None.
For example, the following source data will raise an error:
@dlt.resource
def some_data(updated_at=dlt.sources.incremental("updated_at")):
yield [
{"id": 1, "created_at": 1, "updated_at": 1},
{"id": 2, "created_at": 2, "updated_at": 2},
{"id": 3, "created_at": 4, "updated_at": None},
]
list(some_data())
If you want to load data that includes None values you can transform the records before the incremental processing.
You can add steps to the pipeline that filter, transform, or pivot your data.
It is important to set the insert_at parameter of the add_map function to control the order of the execution and ensure that your custom steps are executed before the incremental processing starts.
In the following example, the step of data yielding is at index = 0, the custom transformation at index = 1, and the incremental processing at index = 2.
See below how you can modify rows before the incremental processing using add_map() and filter rows using add_filter().
@dlt.resource
def some_data(updated_at=dlt.sources.incremental("updated_at")):
yield [
{"id": 1, "created_at": 1, "updated_at": 1},
{"id": 2, "created_at": 2, "updated_at": 2},
{"id": 3, "created_at": 4, "updated_at": None},
]
def set_default_updated_at(record):
if record.get("updated_at") is None:
record["updated_at"] = record.get("created_at")
return record
# modifies records before the incremental processing
with_default_values = some_data().add_map(set_default_updated_at, insert_at=1)
result = list(with_default_values)
assert len(result) == 3
assert result[2]["updated_at"] == 4
# removes records before the incremental processing
without_none = some_data().add_filter(lambda r: r.get("updated_at") is not None, insert_at=1)
result_filtered = list(without_none)
assert len(result_filtered) == 2
Doing a full refresh
You may force a full refresh of a merge and append pipelines:
- In case of a
mergethe data in the destination is deleted and loaded fresh. Currently we do not deduplicate data during the full refresh. - In case of
dlt.sources.incrementalthe data is deleted and loaded from scratch. The state of the incremental is reset to the initial value.
Example:
p = dlt.pipeline(destination="bigquery", dataset_name="dataset_name")
# do a full refresh
p.run(merge_source(), write_disposition="replace")
# do a full refresh of just one table
p.run(merge_source().with_resources("merge_table"), write_disposition="replace")
# run a normal merge
p.run(merge_source())
Passing write disposition to replace will change write disposition on all the resources in
repo_events during the run of the pipeline.
Custom incremental loading with pipeline state
The pipeline state is a Python dictionary which gets committed atomically with the data; you can set values in it in your resources and on next pipeline run, request them back.
The pipeline state is in principle scoped to the resource - all values of the state set by resource are private and isolated from any other resource. You can also access the source-scoped state which can be shared across resources. You can find more information on pipeline state here.
Preserving the last value in resource state.
For the purpose of preserving the “last value” or similar loading checkpoints, we can open a dlt state dictionary with a key and a default value as below. When the resource is executed and the data is loaded, the yielded resource data will be loaded at the same time with the update to the state.
In the two examples below you see how the dlt.sources.incremental is working under the hood.
@resource()
def tweets():
# Get a last value from loaded metadata. If not exist, get None
last_val = dlt.current.resource_state().setdefault("last_updated", None)
# get data and yield it
data = get_data(start_from=last_val)
yield data
# change the state to the new value
dlt.current.state()["last_updated"] = data["last_timestamp"]
If we keep a list or a dictionary in the state, we can modify the underlying values in the objects, and thus we do not need to set the state back explicitly.
@resource()
def tweets():
# Get a last value from loaded metadata. If not exist, get None
loaded_dates = dlt.current.resource_state().setdefault("days_loaded", [])
# do stuff: get data and add new values to the list
# `loaded_date` is a reference to the `dlt.current.resource_state()["days_loaded"]` list
# and thus modifying it modifies the state
yield data
loaded_dates.append('2023-01-01')
Step by step explanation of how to get or set the state:
- We can use the function
var = dlt.current.resource_state().setdefault("key", []). This allows us to retrieve the values ofkey. Ifkeywas not set yet, we will get the default value[]instead. - We now can treat
varas a python list - We can append new values to it, or if applicable we can read the values from previous loads. - On pipeline run, the data will load, and the new
var's value will get saved in the state. The state is stored at the destination, so it will be available on subsequent runs.
Advanced state usage: storing a list of processed entities
Let’s look at the player_games resource from the chess pipeline. The chess API has a method to
request games archives for a given month. The task is to prevent the user to load the same month
data twice - even if the user makes a mistake and requests the same months range again:
- Our data is requested in 2 steps:
- Get all available archives URLs.
- Get the data from each URL.
- We will add the “chess archives” URLs to this list we created.
- This will allow us to track what data we have loaded.
- When the data is loaded, the list of archives is loaded with it.
- Later we can read this list and know what data has already been loaded.
In the following example, we initialize a variable with an empty list as a default:
@dlt.resource(write_disposition="append")
def players_games(chess_url, players, start_month=None, end_month=None):
loaded_archives_cache = dlt.current.resource_state().setdefault("archives", [])
# as far as python is concerned, this variable behaves like
# loaded_archives_cache = state['archives'] or []
# afterwards we can modify list, and finally
# when the data is loaded, the cache is updated with our loaded_archives_cache
# get archives for a given player
archives = get_players_archives(chess_url, players)
for url in archives:
# if not in cache, yield the data and cache the URL
if url not in loaded_archives_cache:
# add URL to cache and yield the associated data
loaded_archives_cache.append(url)
r = requests.get(url)
r.raise_for_status()
yield r.json().get("games", [])
else:
print(f"skipping archive {url}")
Advanced state usage: tracking the last value for all search terms in Twitter API
@dlt.resource(write_disposition="append")
def search_tweets(twitter_bearer_token=dlt.secrets.value, search_terms=None, start_time=None, end_time=None, last_value=None):
headers = _headers(twitter_bearer_token)
for search_term in search_terms:
# make cache for each term
last_value_cache = dlt.current.state().setdefault(f"last_value_{search_term}", None)
print(f'last_value_cache: {last_value_cache}')
params = {...}
url = "https://api.twitter.com/2/tweets/search/recent"
response = _paginated_get(url, headers=headers, params=params)
for page in response:
page['search_term'] = search_term
last_id = page.get('meta', {}).get('newest_id', 0)
#set it back - not needed if we
dlt.current.state()[f"last_value_{search_term}"] = max(last_value_cache or 0, int(last_id))
# print the value for each search term
print(f'new_last_value_cache for term {search_term}: {last_value_cache}')
yield page
Troubleshooting
If you see that the incremental loading is not working as expected and the incremental values are not modified between pipeline runs, check the following:
Make sure the
destination,pipeline_nameanddataset_nameare the same between pipeline runs.Check if
dev_modeisFalsein the pipeline configuration. Check ifrefreshfor associated sources and resources is not enabled.Check the logs for
Bind incremental on <resource_name> ...message. This message indicates that the incremental value was bound to the resource and shows the state of the incremental value.After the pipeline run, check the state of the pipeline. You can do this by running the following command:
dlt pipeline -v <pipeline_name> info
For example, if your pipeline is defined as follows:
@dlt.resource
def my_resource(
incremental_object = dlt.sources.incremental("some_key", initial_value=0),
):
...
pipeline = dlt.pipeline(
pipeline_name="example_pipeline",
destination="duckdb",
)
pipeline.run(my_resource)
You'll see the following output:
Attaching to pipeline <pipeline_name>
...
sources:
{
"example": {
"resources": {
"my_resource": {
"incremental": {
"some_key": {
"initial_value": 0,
"last_value": 42,
"unique_hashes": [
"nmbInLyII4wDF5zpBovL"
]
}
}
}
}
}
}
Verify that the last_value is updated between pipeline runs.