Getting started
Overview
dlt is an open-source library that you can add to your Python scripts to load data
from various and often messy data sources into well-structured, live datasets.
This guide will show you how to start using dlt with a simple example: loading data
from a list of Python dictionaries into DuckDB.
Let's get started!
Installation
Install dlt using pip:
pip install -U dlt
The command above installs (or upgrades) the core library, in the example below we
use DuckDB as a destination so let's add a duckdb dependency:
pip install "dlt[duckdb]"
Use a clean virtual environment for your experiments! Here are detailed instructions.
Make sure that your dlt version is 0.3.15 or above. Check it in the terminal with dlt --version.
Quick start
For starters, let's load a list of Python dictionaries into DuckDB and inspect the created dataset. Here is the code:
import dlt
data = [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}]
pipeline = dlt.pipeline(
pipeline_name="quick_start", destination="duckdb", dataset_name="mydata"
)
load_info = pipeline.run(data, table_name="users")
print(load_info)
When you look at the code above, you can see that we:
- Import the
dltlibrary. - Define our data to load.
- Create a pipeline that loads data into DuckDB. Here we also specify the
pipeline_nameanddataset_name. We'll use both in a moment. - Run the pipeline.
Save this Python script with the name quick_start_pipeline.py and run the following command:
python quick_start_pipeline.py
The output should look like:
Pipeline quick_start completed in 0.59 seconds
1 load package(s) were loaded to destination duckdb and into dataset mydata
The duckdb destination used duckdb:////home/user-name/quick_start/quick_start.duckdb location to store data
Load package 1692364844.460054 is LOADED and contains no failed jobs
dlt just created a database schema called mydata (the dataset_name) with a table users in it.
Explore the data
To allow sneak peek and basic discovery you can take advantage of built-in integration with Strealmit:
dlt pipeline quick_start show
quick_start is the name of the pipeline from the script above. If you do not have Streamlit installed yet do:
pip install streamlit
Now you should see the users table:
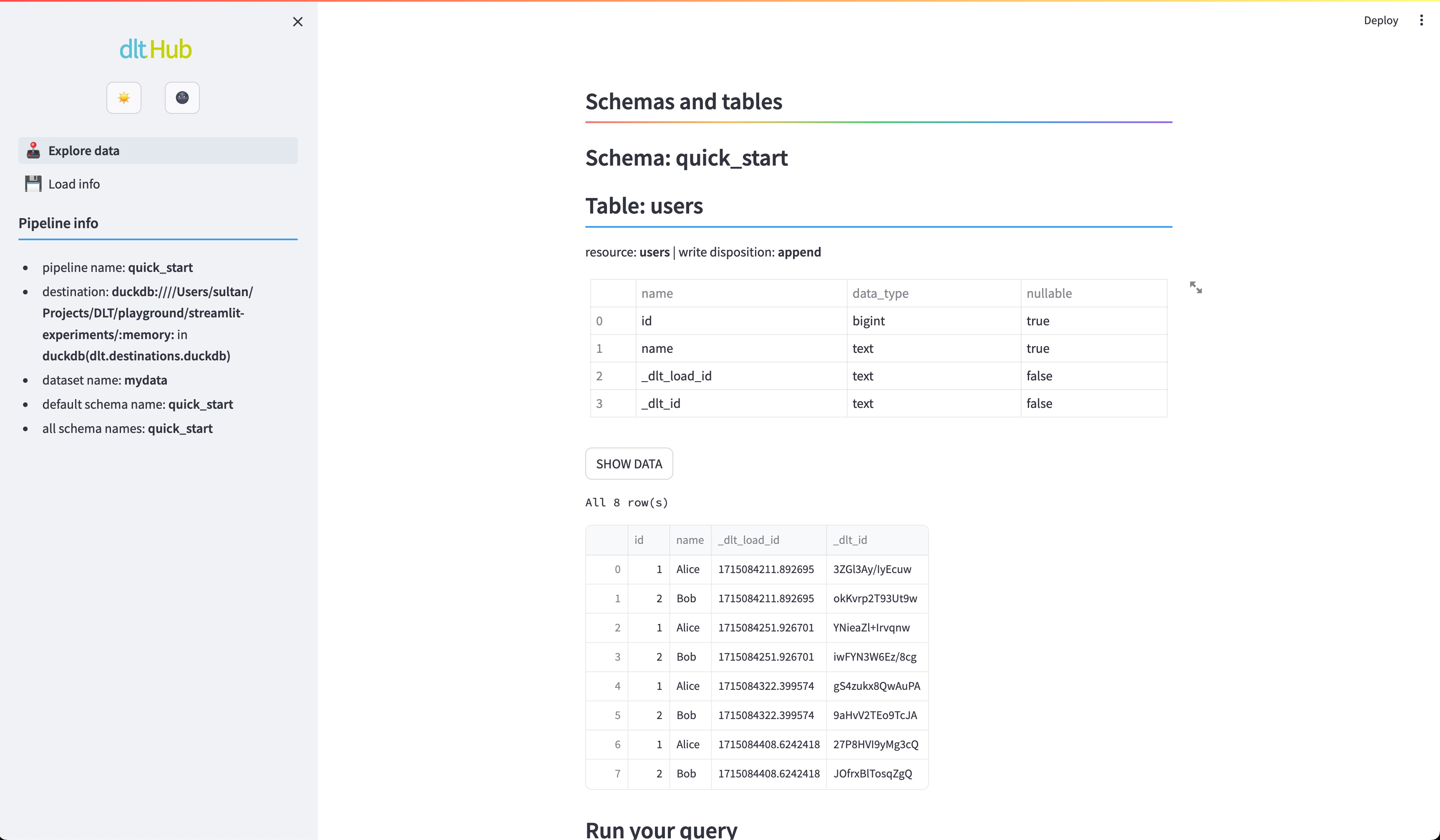 Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
dlt works in Jupyter Notebook and Google Colab! See our Quickstart Colab Demo.
Looking for source code of all the snippets? You can find and run them from this repository.
What's next?
Now that you have a basic understanding of how to get started with dlt, you might be eager to dive deeper. A great next step is to walk through our detailed tutorial, where we provide a step-by-step guide to building a pipeline that loads data from the GitHub API into DuckDB and teaches you how to use some of the most important features of dlt.
More resources: