Building data pipelines with dlt, from basic to advanced
This in-depth overview will take you through the main areas of pipelining with dlt. Go to the
related pages you are instead looking for the quickstart, or the
walkthroughs.
Why build pipelines with dlt?
dlt offers functionality to support the entire extract and load process. Let's look at the high level diagram:
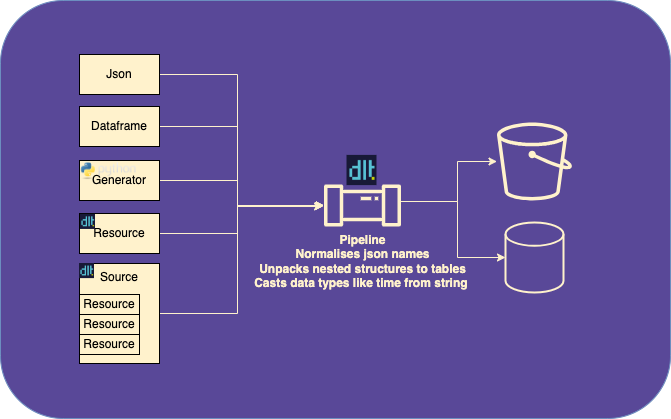
First, we have a pipeline function, that can infer a schema from data and load the data to the destination.
We can use this pipeline with json data, dataframes, or other iterable objects such as generator functions.
This pipeline provides effortless loading via a schema discovery, versioning and evolution engine that ensures you can "just load" any data with row and column level lineage.
By utilizing a dlt pipeline, we can easily adapt and structure data as it evolves, reducing the time spent on
maintenance and development.
This allows our data team to focus on leveraging the data and driving value, while ensuring effective governance through timely notifications of any changes.
For extract, dlt also provides source and resource decorators that enable defining
how extracted data should be loaded, while supporting graceful,
scalable extraction via micro-batching and parallelism.
The simplest pipeline: 1 liner to load data with schema evolution
import dlt
dlt.pipeline(destination='duckdb', dataset_name='mydata').run([{'id': 1, 'name': 'John'}], table_name="users")
A pipeline in the dlt library is a powerful tool that allows you to move data from your Python code
to a destination with a single function call. By defining a pipeline, you can easily load,
normalize, and evolve your data schemas, enabling seamless data integration and analysis.
For example, let's consider a scenario where you want to load a list of objects into a DuckDB table
named "three". With dlt, you can create a pipeline and run it with just a few lines of code:
- Create a pipeline to the destination.
- Give this pipeline data and run it.
import dlt
pipeline = dlt.pipeline(destination="duckdb", dataset_name="country_data")
data = [
{'country': 'USA', 'population': 331449281, 'capital': 'Washington, D.C.'},
{'country': 'Canada', 'population': 38005238, 'capital': 'Ottawa'},
{'country': 'Germany', 'population': 83019200, 'capital': 'Berlin'}
]
info = pipeline.run(data, table_name="countries")
print(info)
In this example, the pipeline function is used to create a pipeline with the specified
destination (DuckDB) and dataset name ("country_data"). The run method is then called to load
the data from a list of objects into the table named "countries". The info variable stores
information about the loaded data, such as package IDs and job metadata.
The data you can pass to it should be iterable: lists of rows, generators, or dlt sources will do
just fine.
If you want to configure how the data is loaded, you can choose between write_dispositions
such as replace, append and merge in the pipeline function.
Here is an example where we load some data to duckdb by upserting or merging on the id column found in the data.
In this example, we also run a dbt package and then load the outcomes of the load jobs into their respective tables.
This will enable us to log when schema changes occurred and match them to the loaded data for lineage, granting us both column and row level lineage.
We also alert the schema change to a Slack channel where hopefully the producer and consumer are subscribed.
import dlt
# have data? dlt likes data
data = [{'id': 1, 'name': 'John'}]
# open connection
pipeline = dlt.pipeline(
destination='duckdb',
dataset_name='raw_data'
)
# Upsert/merge: Update old records, insert new
load_info = pipeline.run(
data,
write_disposition="merge",
primary_key="id",
table_name="users"
)
Add dbt runner, optionally with venv:
venv = dlt.dbt.get_venv(pipeline)
dbt = dlt.dbt.package(
pipeline,
"https://github.com/dbt-labs/jaffle_shop.git",
venv=venv
)
models_info = dbt.run_all()
# Load metadata for monitoring and load package lineage.
# This allows for both row and column level lineage,
# as it contains schema update info linked to the loaded data
pipeline.run([load_info], table_name="loading_status", write_disposition='append')
pipeline.run([models_info], table_name="transform_status", write_disposition='append')
Let's alert any schema changes:
from dlt.common.runtime.slack import send_slack_message
slack_hook = "https://hooks.slack.com/services/xxx/xxx/xxx"
for package in load_info.load_packages:
for table_name, table in package.schema_update.items():
for column_name, column in table["columns"].items():
send_slack_message(
slack_hook,
message=f"\tTable updated: {table_name}: Column changed: {column_name}: {column['data_type']}"
)
Extracting data with dlt
Extracting data with dlt is simple - you simply decorate your data-producing functions with loading
or incremental extraction metadata, which enables dlt to extract and load by your custom logic.
Technically, two key aspects contribute to dlt's effectiveness:
- Scalability through iterators, chunking, parallelization.
- The utilization of implicit extraction DAGs that allow efficient API calls for data enrichments or transformations.
Scalability via iterators, chunking, and parallelization
dlt offers scalable data extraction by leveraging iterators, chunking, and parallelization
techniques. This approach allows for efficient processing of large datasets by breaking them down
into manageable chunks.
For example, consider a scenario where you need to extract data from a massive database with
millions of records. Instead of loading the entire dataset at once, dlt allows you to use
iterators to fetch data in smaller, more manageable portions. This technique enables incremental
processing and loading, which is particularly useful when dealing with limited memory resources.
Furthermore, dlt facilitates parallelization during the extraction process. By processing
multiple data chunks simultaneously, dlt takes advantage of parallel processing capabilities,
resulting in significantly reduced extraction times. This parallelization enhances performance,
especially when dealing with high-volume data sources.
Implicit extraction DAGs
dlt incorporates the concept of implicit extraction DAGs to handle the dependencies between
data sources and their transformations automatically. A DAG represents a directed graph without
cycles, where each node represents a data source or transformation step.
When using dlt, the tool automatically generates an extraction DAG based on the dependencies
identified between the data sources and their transformations. This extraction DAG determines the
optimal order for extracting the resources to ensure data consistency and integrity.
For instance, imagine a pipeline where data needs to be extracted from multiple API endpoints and
undergo certain transformations or enrichments via additional calls before loading it into a
database. dlt analyzes the dependencies between the API endpoints and transformations and
generates an extraction DAG accordingly. The extraction DAG ensures that the data is extracted in
the correct order, accounting for any dependencies and transformations.
When deploying to Airflow, the internal DAG is unpacked into Airflow tasks in such a way to ensure consistency and allow granular loading.
Defining Incremental Loading
Incremental loading is a crucial concept in data pipelines that involves loading only new or changed data instead of reloading the entire dataset. This approach provides several benefits, including low-latency data transfer and cost savings.
Declarative loading
Declarative loading allows you to specify the desired state of the data in the target destination,
enabling efficient incremental updates. With dlt, you can define the incremental loading
behavior using the write_disposition parameter. There are three options available:
- Full load: This option replaces the entire destination dataset with the data produced by the
source on the current run. You can achieve this by setting
write_disposition='replace'in your resources. It is suitable for stateless data that doesn't change, such as recorded events like page views. - Append: The append option adds new data to the existing destination dataset. By using
write_disposition='append', you can ensure that only new records are loaded. This is suitable for stateless data that can be easily appended without any conflicts. - Merge: The merge option is used when you want to merge new data with the existing destination
dataset while also handling deduplication or upserts. It requires the use of
merge_keyand/orprimary_keyto identify and update specific records. By settingwrite_disposition='merge', you can perform merge-based incremental loading.
For example, let's say you want to load GitHub events and update them in the destination, ensuring that only one instance of each event is present.
You can use the merge write disposition as follows:
@dlt.resource(primary_key="id", write_disposition="merge")
def github_repo_events():
yield from _get_event_pages()
In this example, the github_repo_events resource uses the merge write disposition with
primary_key="id". This ensures that only one copy of each event, identified by its unique ID,
is present in the github_repo_events table. dlt takes care of loading the data
incrementally, deduplicating it, and performing the necessary merge operations.
Advanced state management
Advanced state management in dlt allows you to store and retrieve values across pipeline runs
by persisting them at the destination but accessing them in a dictionary in code. This enables you
to track and manage incremental loading effectively. By leveraging the pipeline state, you can
preserve information, such as last values, checkpoints or column renames, and utilize them later in
the pipeline.
Transforming the Data
Data transformation plays a crucial role in the data loading process. You can perform transformations both before and after loading the data. Here's how you can achieve it:
Before Loading
Before loading the data, you have the flexibility to perform transformations using Python. You can leverage Python's extensive libraries and functions to manipulate and preprocess the data as needed. Here's an example of pseudonymizing columns before loading the data.
In the above example, the pseudonymize_name function pseudonymizes the name column by
generating a deterministic hash using SHA256. It adds a salt to the column value to ensure
consistent mapping. The dummy_source generates dummy data with an id and name
column, and the add_map function applies the pseudonymize_name transformation to each
record.
After Loading
For transformations after loading the data, you have several options available:
Using dbt
dbt is a powerful framework for transforming data. It enables you to structure your transformations
into DAGs, providing cross-database compatibility and various features such as templating,
backfills, testing, and troubleshooting. You can use the dbt runner in dlt to seamlessly
integrate dbt into your pipeline. Here's an example of running a dbt package after loading the data:
import dlt
from pipedrive import pipedrive_source
# load to raw
pipeline = dlt.pipeline(
pipeline_name='pipedrive',
destination='bigquery',
dataset_name='pipedrive_raw'
)
load_info = pipeline.run(pipedrive_source())
print(load_info)
Now transform from loaded data to dbt dataset:
pipeline = dlt.pipeline(
pipeline_name='pipedrive',
destination='bigquery',
dataset_name='pipedrive_dbt'
)
# make venv and install dbt in it.
venv = dlt.dbt.get_venv(pipeline)
# get package from local or github link and run
dbt = dlt.dbt.package(pipeline, "pipedrive/dbt_pipedrive/pipedrive", venv=venv)
models = dbt.run_all()
# show outcome
for m in models:
print(f"Model {m.model_name} materialized in {m.time} with status {m.status} and message {m.message}")
In this example, the first pipeline loads the data using pipedrive_source(). The second
pipeline performs transformations using a dbt package called pipedrive after loading the data.
The dbt.package function sets up the dbt runner, and dbt.run_all() executes the dbt
models defined in the package.
Using the dlt SQL client
Another option is to leverage the dlt SQL client to query the loaded data and perform
transformations using SQL statements. You can execute SQL statements that change the database schema
or manipulate data within tables. Here's an example of inserting a row into the customers
table using the dlt SQL client:
pipeline = dlt.pipeline(destination="bigquery", dataset_name="crm")
with pipeline.sql_client() as client:
client.execute_sql(
"INSERT INTO customers VALUES (%s, %s, %s)", 10, "Fred", "fred@fred.com"
)
In this example, the execute_sql method of the SQL client allows you to execute SQL
statements. The statement inserts a row with values into the customers table.
Using Pandas
You can fetch query results as Pandas data frames and perform transformations using Pandas
functionalities. Here's an example of reading data from the issues table in DuckDB and
counting reaction types using Pandas:
pipeline = dlt.pipeline(
pipeline_name="github_pipeline",
destination="duckdb",
dataset_name="github_reactions",
dev_mode=True
)
with pipeline.sql_client() as client:
with client.execute_query(
'SELECT "reactions__+1", "reactions__-1", reactions__laugh, reactions__hooray, reactions__rocket FROM issues'
) as table:
reactions = table.df()
counts = reactions.sum(0).sort_values(0, ascending=False)
By leveraging these transformation options, you can shape and manipulate the data before or after loading it, allowing you to meet specific requirements and ensure data quality and consistency.
Adjusting the automated normalisation
To streamline the process, dlt recommends attaching schemas to sources implicitly instead of
creating them explicitly. You can provide a few global schema settings and let the table and column
schemas be generated from the resource hints and the data itself. The dlt.source decorator accepts a
schema instance that you can create and modify within the source function. Additionally, you can
store schema files with the source Python module and have them automatically loaded and used as the
schema for the source.
By adjusting the automated normalization process in dlt, you can ensure that the generated database
schema meets your specific requirements and aligns with your preferred naming conventions, data
types, and other customization needs.
Customizing the Normalization Process
Customizing the normalization process in dlt allows you to adapt it to your specific requirements.
You can adjust table and column names, configure column properties, define data type autodetectors, apply performance hints, specify preferred data types, or change how ids are propagated in the unpacking process.
These customization options enable you to create a schema that aligns with your desired naming
conventions, data types, and overall data structure. With dlt, you have the flexibility to tailor
the normalization process to meet your unique needs and achieve optimal results.
Read more about how to configure schema generation.
Exporting and Importing Schema Files
dlt allows you to export and import schema files, which contain the structure and instructions for
processing and loading the data. Exporting schema files enables you to modify them directly, making
adjustments to the schema as needed. You can then import the modified schema files back into dlt to
use them in your pipeline.
Read more: Adjust a schema docs.
Governance Support in dlt Pipelines
dlt pipelines offer robust governance support through three key mechanisms: pipeline metadata
utilization, schema enforcement and curation, and schema change alerts.
Pipeline Metadata
dlt pipelines leverage metadata to provide governance capabilities. This metadata includes load IDs,
which consist of a timestamp and pipeline name. Load IDs enable incremental transformations and data
vaulting by tracking data loads and facilitating data lineage and traceability.
Read more about lineage.
Schema Enforcement and Curation
dlt empowers users to enforce and curate schemas, ensuring data consistency and quality. Schemas
define the structure of normalized data and guide the processing and loading of data. By adhering to
predefined schemas, pipelines maintain data integrity and facilitate standardized data handling
practices.
Read more: Adjust a schema docs.
Schema evolution
dlt enables proactive governance by alerting users to schema changes. When modifications occur in
the source data’s schema, such as table or column alterations, dlt notifies stakeholders, allowing
them to take necessary actions, such as reviewing and validating the changes, updating downstream
processes, or performing impact analysis.
These governance features in dlt pipelines contribute to better data management practices,
compliance adherence, and overall data governance, promoting data consistency, traceability, and
control throughout the data processing lifecycle.
Scaling and finetuning
dlt offers several mechanism and configuration options to scale up and finetune pipelines:
- Running extraction, normalization and load in parallel.
- Writing sources and resources that are run in parallel via thread pools and async execution.
- Finetune the memory buffers, intermediary file sizes and compression options.
Read more about performance.
Other advanced topics
dlt is a constantly growing library that supports many features and use cases needed by the
community. Join our Slack
to find recent releases or discuss what you can build with dlt.