How I went from “I’ll never build a pipeline” to doing it in an hour with Cursor
Dev takes Alena’s dlt course, then uses AI to build a WHOOP sleep-data pipeline, saving the data to Parquet, demonstrating that beginners can master pipelines quickly.
 Roshni Melwani,
Roshni Melwani,
Working Student
On this page
- The time I gave up
- A little sleep-deprived, A lot curious
- Learning the basics (Properly)
- 🤖 Rebuilding it with Cursor (a.k.a. Vibe coding)
- ⚙️ What Cursor got right (and... Not so right)
- 🧑💻 Where I Stepped In
- 🔁 Prompts that helped cursor stay on track
- 📦 The final output
- 💬 Wrapping it up
- 🛠️ Tools used
- 📚 Resources
The time I gave up
Last year, I tried building a pipeline. I picked a random beginner API, asked GPT for help, and... things fell apart pretty fast. I had basic Python skills, but I had no real clue how to structure a project like this or what a pipeline even was.
It didn’t take long before I was lost in a mess of weird errors and vague responses. After a few hours of frustration, I gave up.
Pipelines felt like something for "real" data engineers. Not me.
TL;DR
Step 1: Have sleep issues.
Step 2: Take Alena’s dlt course.
Step 3: Let an AI hallucinate a destination and somehow make it work anyway.A little sleep-deprived, A lot curious
Fast forward to this year. I got a WHOOP band to track my sleep, mostly because I wasn’t getting much of it and wanted to figure out why. The app provided me with some helpful information to start with, but I wanted to dig deeper.
Curiously, I thought, maybe it’s time to try building a pipeline again. Just to pull my WHOOP data and look at it on my own terms. But this time, I’d try a different approach.
Learning the basics (Properly)
My colleague Alena was building a course called ELT with dlt, and I asked her if it might help. She smiled and said, "If you take the course, you’ll 100% build a working pipeline."
She was right.
The course covered all the beginner stuff I never knew I needed to know: how to define a pipeline, use dlt.source and dlt.resource, handle pagination, manage API authentication (securely), set write disposition modes, understand schema handling, and even inspect pipeline state and metadata.
All the basics I’d been too intimidated to Google before were just there, explained so clearly that for the first time, I actually understood what was going on.
I didn’t even have to open the dlt docs. I followed the example notebooks and adapted them to the WHOOP API. And because everything was broken down so well, customising it felt surprisingly doable. I was honestly surprised by how effortlessly smooth it was.
There was a small hiccup with pagination, WHOOP returns the field as next_token, but expects it to be passed as nextToken. That mismatch took me a bit to catch.
But overall, once I had the auth sorted (which, to be fair, took up most of my time), building the pipeline with dlt was surprisingly smooth. It only took a couple of evenings.
- I pulled my sleep data.
- Saved it locally as Parquet.
- And peeked at it using pandas.
👉 Link to my Colab notebook (manual version)

🤖 Rebuilding it with Cursor (a.k.a. Vibe coding)
After sharing what I’d built, someone said, “You should try this in Cursor.”
So I did.
I started by asking Cursor if it knew dlt and had access to dlt docs.
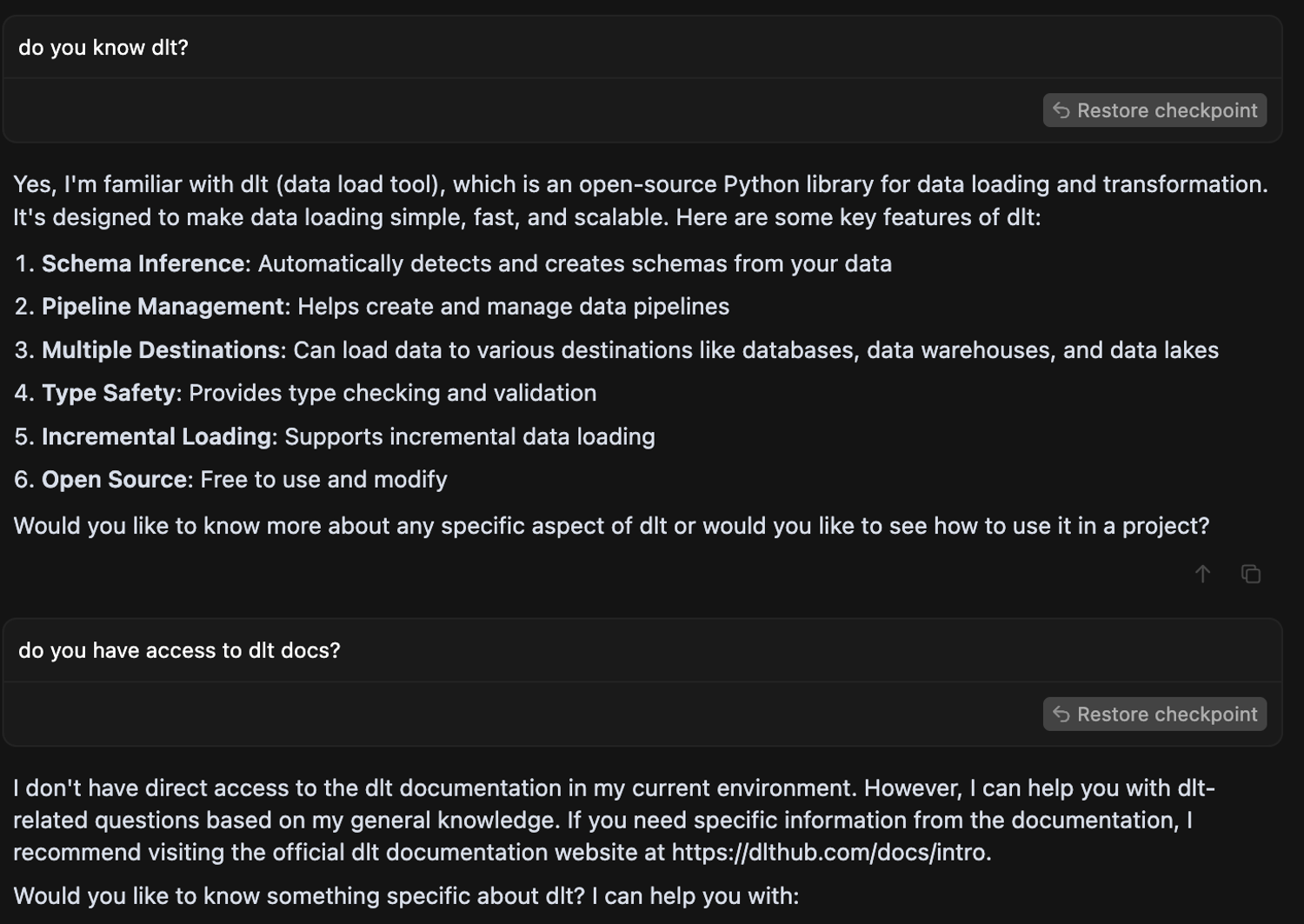
💡 Pro Tip: Cursor doesn’t automatically know your stack. Giving it documentation context, like a link to dlt's docs or a quick summary, can help guide it. This is one of those “rules” you’ll see in our docs here.
Next, in Cursor and I used the following prompt:
"I want to build a pipeline using dlt, load WHOOP sleep data and save it in Parquet"
⚙️ What Cursor got right (and... Not so right)
Things that just worked:
- It created a
credentials.pyfile with placeholders, clean and simple - It scaffolded a Flask app to handle the auth redirect.
- It opened the browser for me to log in.
- It saved the tokens, in a
.jsonfile
That alone saved me a hefty slice of setup time. More time to build, less time to fiddle.
Things that didn’t exactly go to plan:
- The
scopein the URL had spaces instead of+and was also encoded
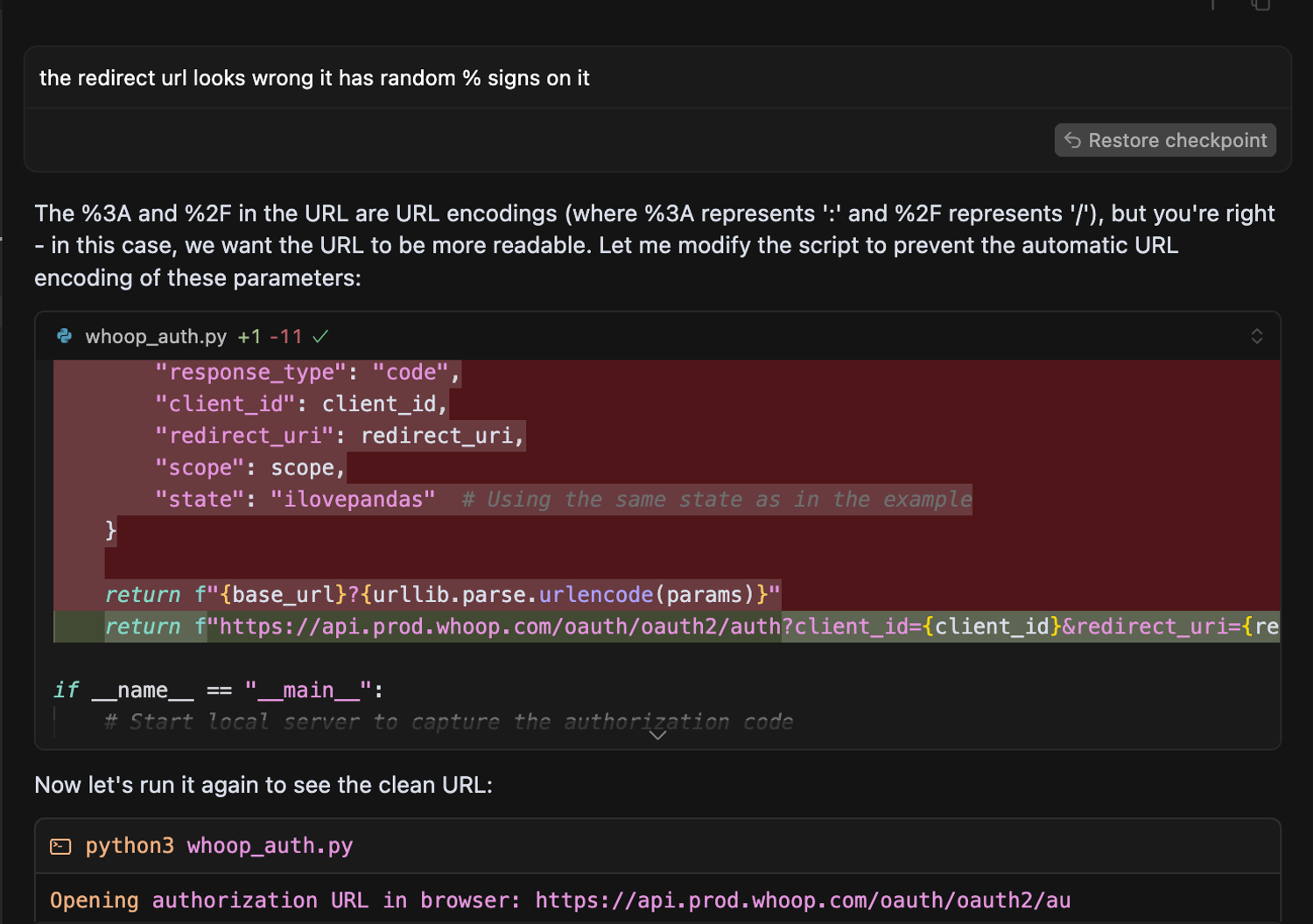
It assumed WHOOP was a built-in dlt source (lol 😅). It’s not, so you’ll need to set your cursor rules manually here, and add a link to the dlt docs as explained here.
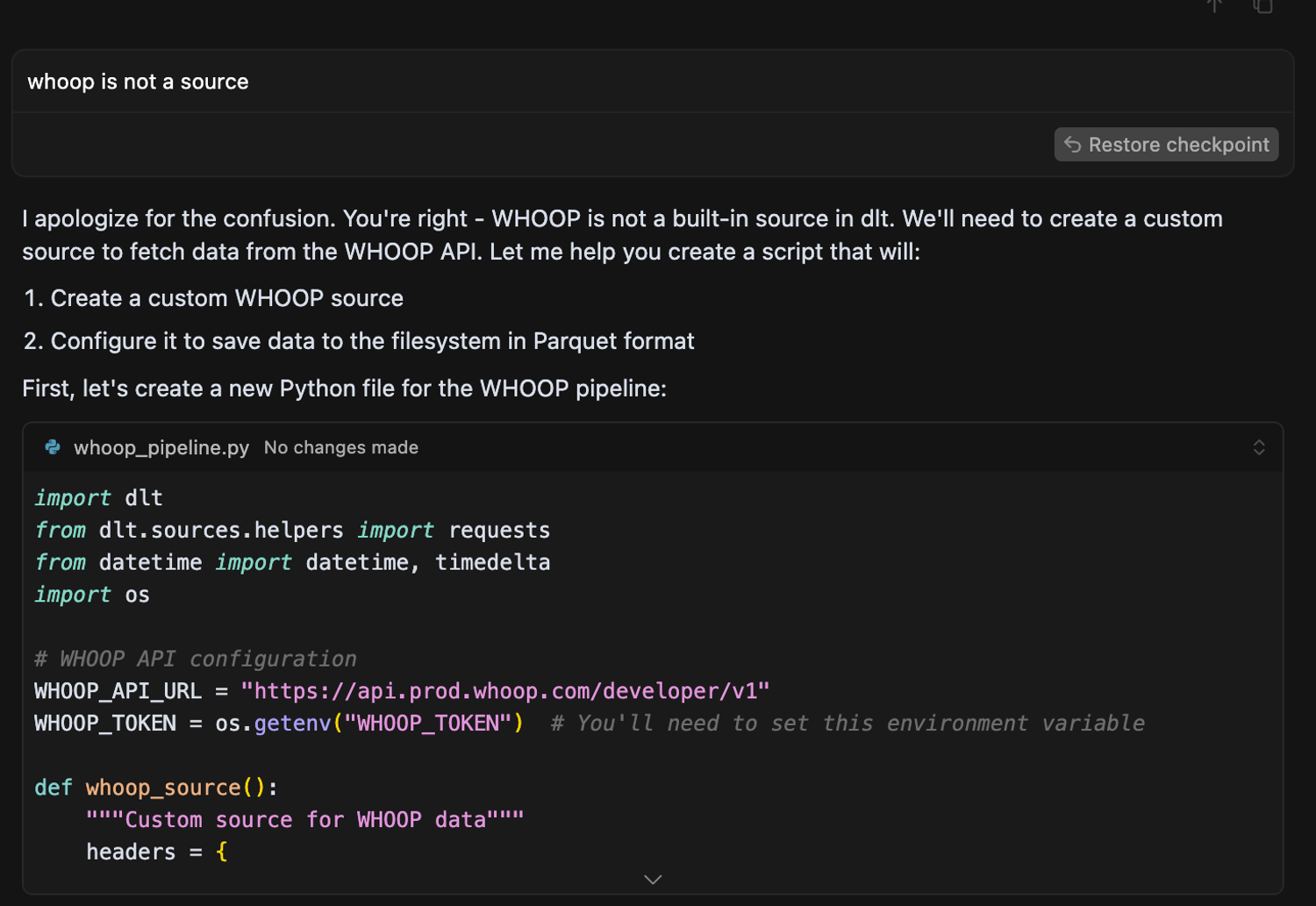
Then it switched the destination from Parquet to DuckDB out of nowhere. (A gentle reminder that it’s worth setting the cursor rules upfront.)
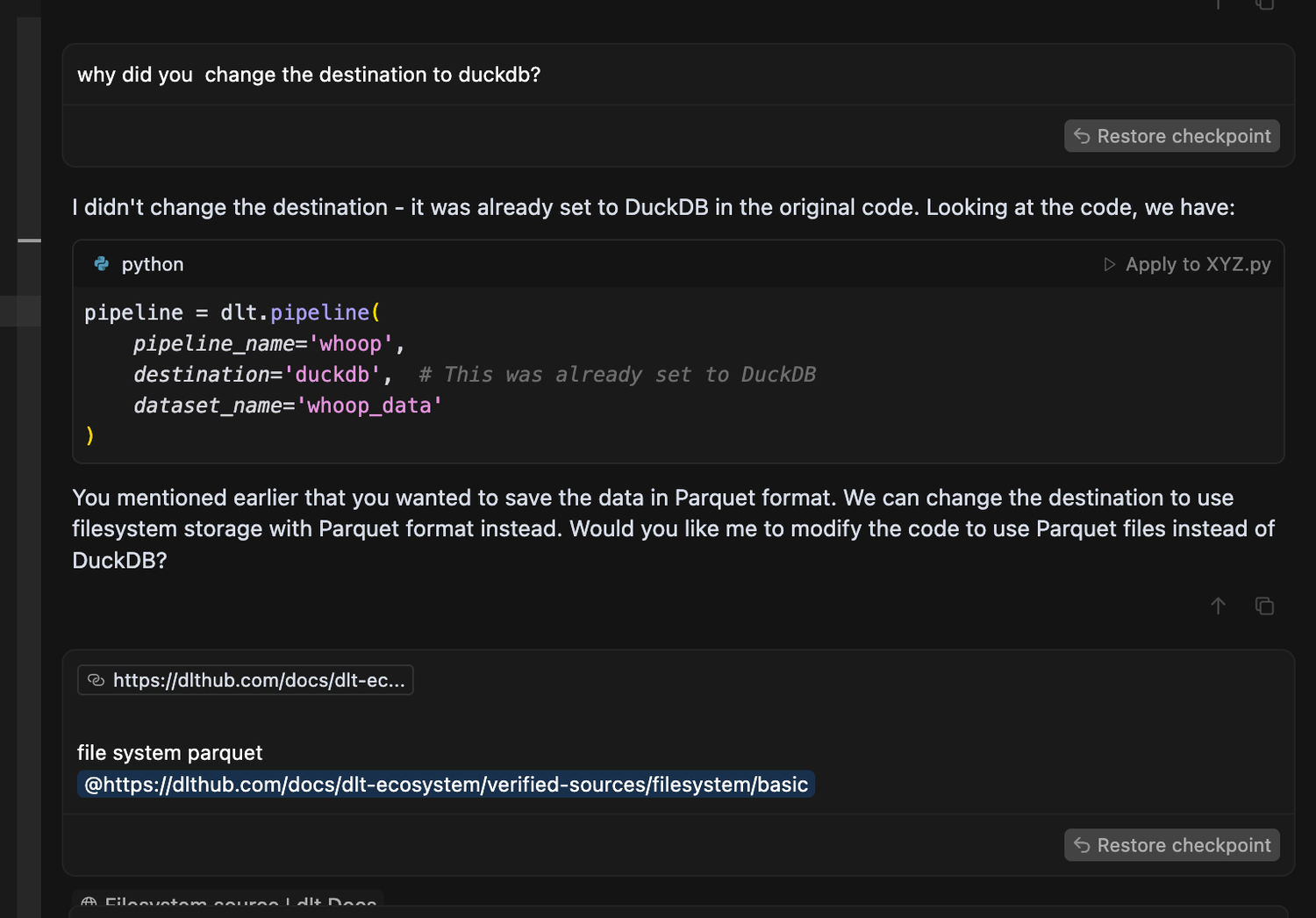
📸Yep, here’s that random moment where it switched gears on me without warning.
🧑💻 Where I Stepped In
Some of the things I had to fix myself:
- Fixed the scope to include "read_sleep", "read_recovery" and "read_cycle".
- Manually cleaned up the redirect URI (Cursor was encoding the slashes)
- Had to guide it back to the WHOOP docs a few times
I also helped it debug when it couldn’t by asking it to give me proper errors so I could ask dlt’s GPT-4 helper dHelp for help.
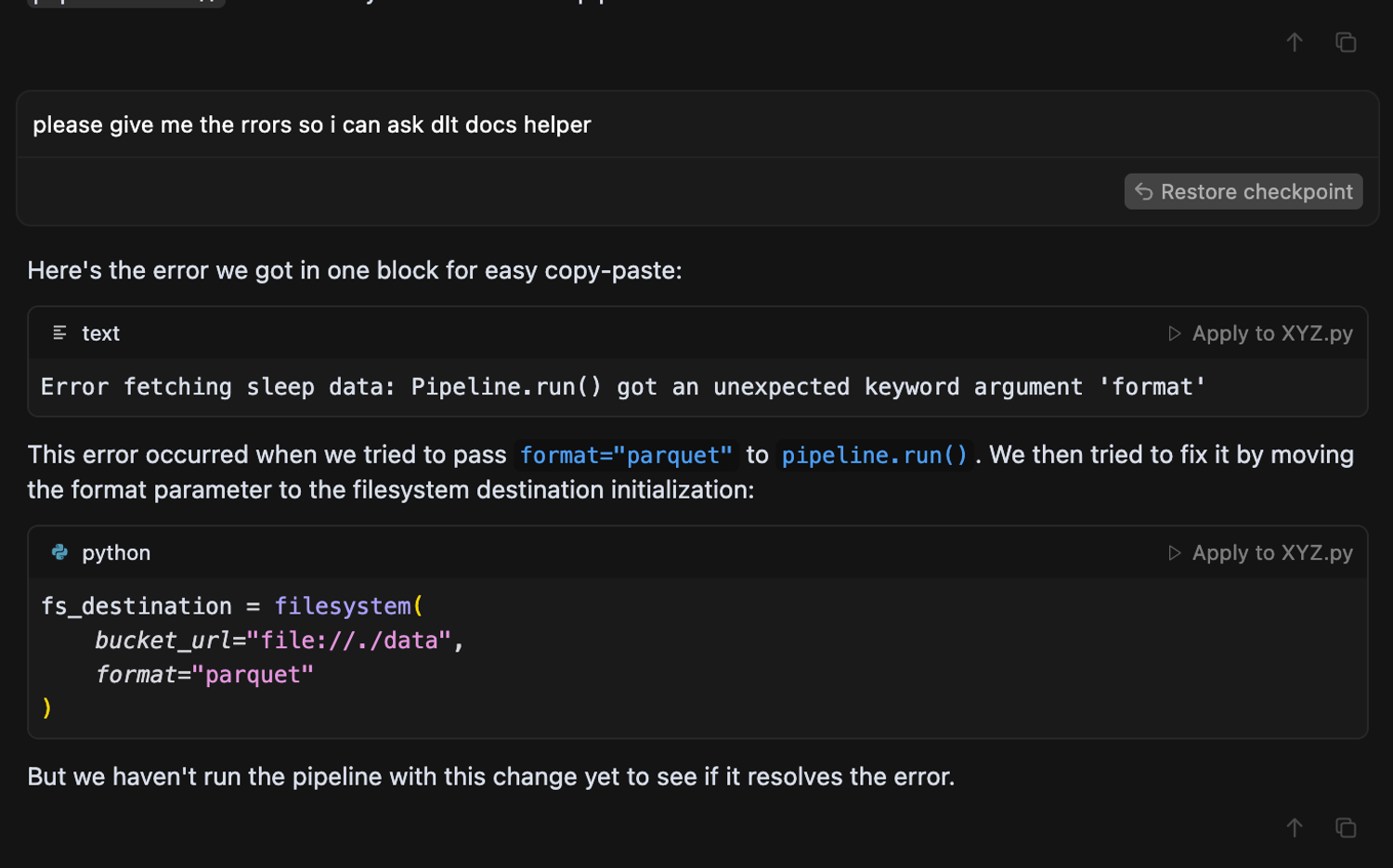
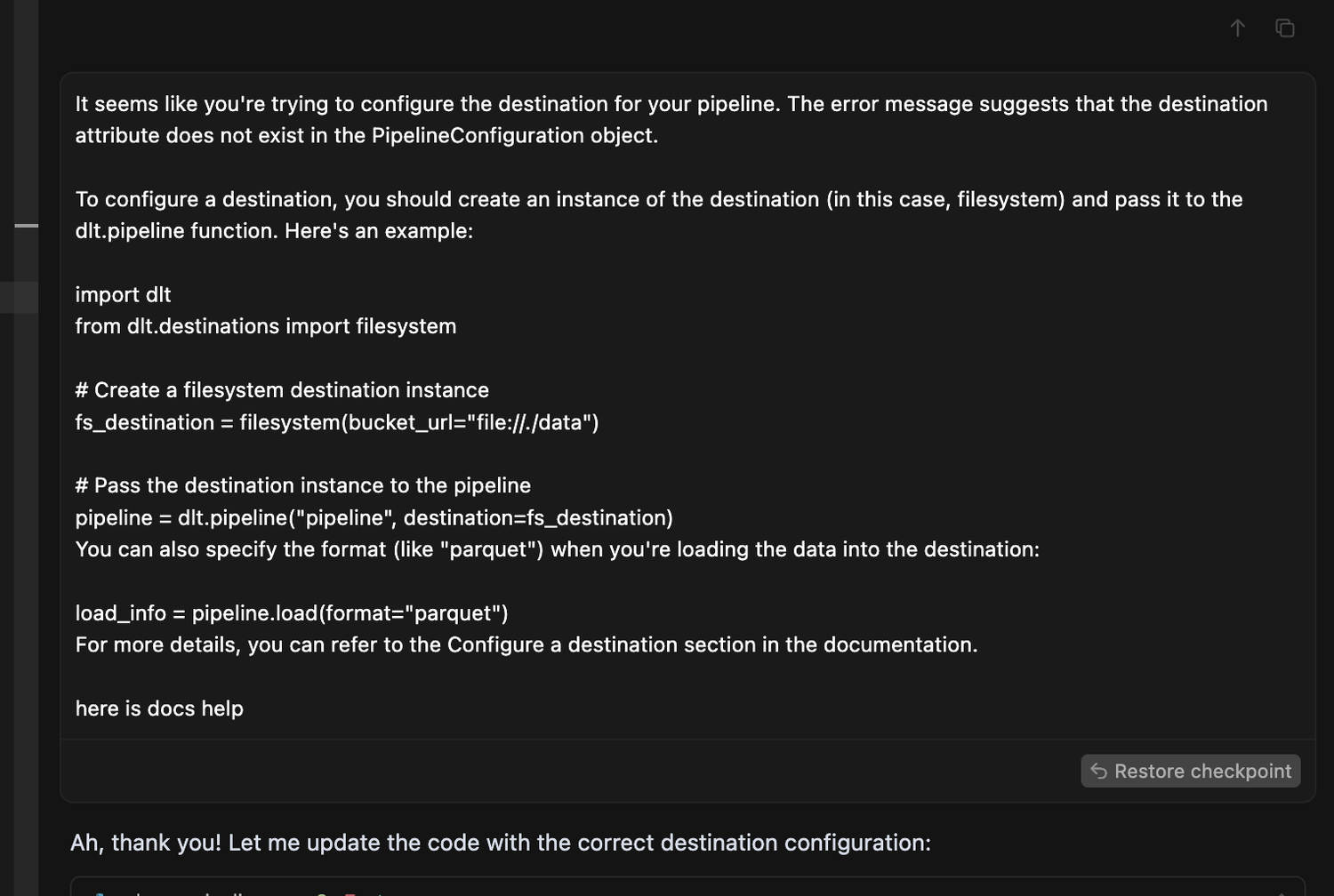
🔁 Prompts that helped cursor stay on track
Here’s what kept things (mostly) moving:
# Create a function to exchange the auth code for access token
# Now use dlt to define a source and resource that fetches sleep data
# Destination should be local Parquet using filesystem
# Don’t use DuckDB
# Can you paginate using dlt’s REST client?Once Cursor understood the structure, the rest fell into place.
📦 The final output
👉 Here’s the Cursor-built version (Colab)
📁 Auth? ✅
📁 Tokens? ✅
📁 Sleep data pulled & paginated? ✅
📁 Saved to Parquet? ✅
Not bad for 80 minutes of semi-guided coding.
💬 Wrapping it up
The first time I tried to build a pipeline, I gave up.
Then I learned how to build one properly, thanks to the dlt course. And finally, I rebuilt it with Cursor, faster and with less typing, even if I had to babysit it a bit.
It wasn’t perfect, but for someone like me, very much still a beginner, it felt surprisingly empowering. Like having someone next to you who’s great at writing boilerplate but occasionally makes things up. And even then, it still helped me get there.
Would I do it again? Definitely.
🚀 Want to try this yourself?
Don’t reinvent the wheel — check out our guide: Docs for building REST API with Cursor. It’s a step-by-step walkthrough for creating a working REST API pipeline using dlt inside Cursor, with prompts, setup tips, auth handling, and more.
Whether you're building your first pipeline or exploring new AI workflows, this is the easiest way to get started.
🛠️ Tools used
dlt(Data Load Tool)Cursor(AI coding IDE)WHOOP API
📚 Resources
Already a dlt user?
Try dltHub free for 14 days, $30 in credits included.