A Practitioner’s Guide to LLM-native Pipeline Building with dltHub Workspace
LLM-native scaffolds for 1000+ APIs. The IKEA moment in data engineering is here. Build pipelines with LLMs, faster and cleaner.
 Adrian Brudaru,
Adrian Brudaru,
Co-Founder & CDO
As the initial dltHub Workspace workflow, we’re releasing LLM-native dlt pipeline development for 1000+ REST API data sources.
Developers can init any available LLM-native pipeline scaffolding. The scaffolding gives LLMs the context they need to assemble reliable pipelines - and they’re ready to use standalone, in any IDE, starting now.
The IKEA moment in data engineering
For centuries, furniture was handcrafted piece by piece from raw wood. Then IKEA arrived, replacing raw carpentry with standardised parts, simplified assembly, and clear instructions. From weeks of skilled woodworking, we got to hours of simple assembly. Suddenly, quality furniture became affordable and accessible to anyone with a screwdriver.
Today, data engineering is on the verge of a similar shift: from handcrafted pipelines to modular, assembly-driven development - where the raw material isn't particle board, but context.
Assemble pipelines in minutes
The first building block of dltHub Workspace is our approach to context scaffolding: ready-made documentation that give LLMs everything they need to generate a working data pipeline in minutes, not days.
Each scaffold provides:
- LLM-native source docs – API references distilled and structured for model input
- A pipeline starter template – a
dltpipeline template that the LLM can “fill-in” - Rules – guidance that keeps the LLM grounded to correctly assemble pipeline code.
Human-first, human-last
Context scaffolds drastically speed up pipeline creation, but your role as a human remains central.
Only you have:
- Contextual knowledge of your business: what data matters, how fresh it needs to be, and how it'll be used.
- Direct access to your applications to validate that the data pulled matches reality.
- The ability to cross-check outputs with your team, stakeholders, or subject-matter experts to ensure accuracy and usefulness.
An LLM-native scaffold gets you fast to running code, but the pipeline’s, correctness, and ultimate value rely on your judgment. Scaffolds empower you, they don’t replace you.
Making a quality pipeline, much faster
Traditionally, building a data pipeline meant reading documentation, writing code, and troubleshooting until things worked. Now, the docs are distilled into the scaffold, and the code is only a few prompts away.
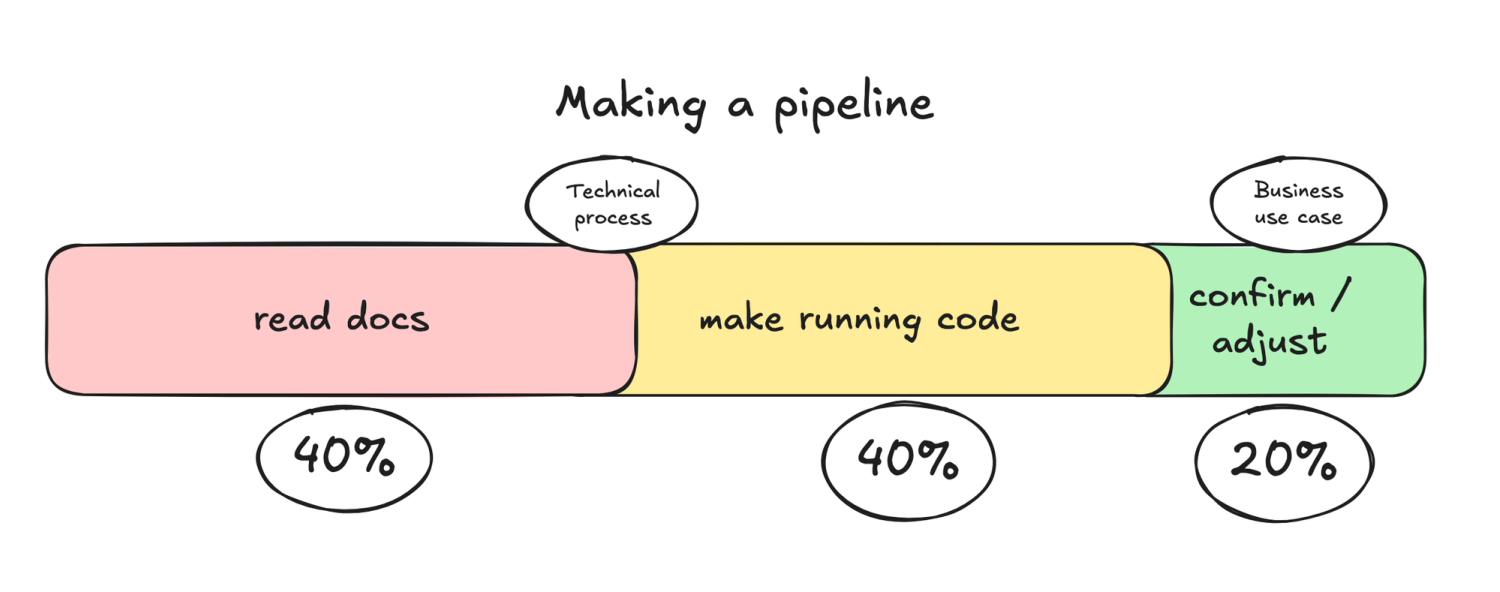
The workflow for pipeline creation becomes simple and fast:
- pip Install workspace and init a LLM-native pipeline scaffold for your data source.
- Generate pipeline code from the context using LLMs.
- Run, customise and debug the pipeline logic using the dltHub Pipeline dashboard
- Test and deploy.
So… what’s next?
We’re building dltHub Workspace into a full local-first platform for AI-assisted pipeline development, starting with context scaffolds today.
Soon, you’ll be able to:
- Explore and use scaffolds directly in the Workspace
- Use LLM assist to compose pipelines, not just generate them
- One-click deploy to a runtime agent that handles orchestration and management
- Work in a cohesive, AI-native loop from idea to production
You can already use scaffolds in your IDE and inspect outputs in the dlt dashboard. Over the next few months, we’ll bring the rest of the experience together.
🔍 Questions you might still have
Data engineer's questions
- Q: How do scaffolds ensure generated code quality and reliability? A: We use dlt’s REST API template to keep LLM code generation task minimal and instead rely on dlt boilerplate. Ensure that the generated configuration is correctly loading your data.
- Q: Can scaffolds handle incremental loading and pagination reliably? A: Generally yes if the information is present in the official documentation. If not, the LLM will attempt a best guess, so make sure you test the outcome.
- Q: Are scaffold-generated pipelines production-ready, or do they always need manual adjustments? A: Scaffolds give you a strong starting point but they don’t replace the developer. You’re still responsible for validating business logic, reviewing edge cases, and customising as needed for production.
- Q: How do scaffolds help with pipeline maintenance, readability, and long-term stability? A: You can optionally re-use the scaffold when making changes to your pipeline.
Non-Engineer Data Professional's questions:
- Q: Do I need to deeply understand Python to use scaffolds effectively? A: No. Scaffolds generate readable Python configuration code. You can quickly extend or modify pipelines even with basic or no Python knowledge.
- Q: What exactly do scaffolds output - are they ready-to-run pipelines or just code snippets? A: Scaffolds help generate complete, ready-to-run Python pipelines.
- Q: If the generated pipeline doesn't fetch all the data I need, what should I do? A: You can easily modify the generated code to include additional endpoints or fields. Prompt your LLM to add them or add them yourself after the LLM generated the rest of the details.
General Questions
- Q: Do scaffolds only work for REST APIs, or can I integrate other sources as well? A: Currently, scaffolds are optimized for REST APIs. However, if you need something else, you can remove or modify the built-in rules and build a pipeline from scratch using standard Python with
dlt. - Q: If my API isn’t available in your scaffold library, can I still use scaffolds somehow? A: Scaffolds are designed for high accuracy and low cost, but you can add any other types of source documentation to your IDE to help with your development process.
- Q: Are scaffolds a permanent part of the pipeline, or can I remove them later and still keep using dlt? A: You can freely remove scaffold-specific components at any time and continue using the dlt pipeline outside LLM workflows.