We’re building dltHub to make data engineering accessible for all Python developers
We’re excited to announce that we’re building dltHub, an LLM-native data engineering platform that enables any Python developer to build, run dlt pipelines, and deliver valuable end-user-ready reports.
 Matthaus Krzykowski,
Matthaus Krzykowski,
Co-Founder & CEO
On this page
- Challenge: Creating and maintaining reliable data pipelines has traditionally been the domain of experienced data professionals
- Solution: Introducing dltHub, so that any Python developer can bring their business users closer to fresh, reliable data
- Background: In the last two months, users have increasingly used LLMs to create dlt pipelines
- Why now: This is why we introduce LLM-native dlt pipeline development as the initial dltHub workflow
- Roadmap
- Demos
- LLM-Native Development of an OpenAI API cost monitoring dlt pipeline
- Utilizing the Pipeline Dashboard for data debugging and the Notebook to create a report of weekly OpenAI API costs for an end user
We’re excited to announce that we’re building dltHub, an LLM-native data engineering platform that enables any Python developer to build, run dlt pipelines, and deliver valuable end-user-ready reports.
We are also releasing the initial dltHub workflow: LLM-native pipeline development for 1,000+ REST API sources.
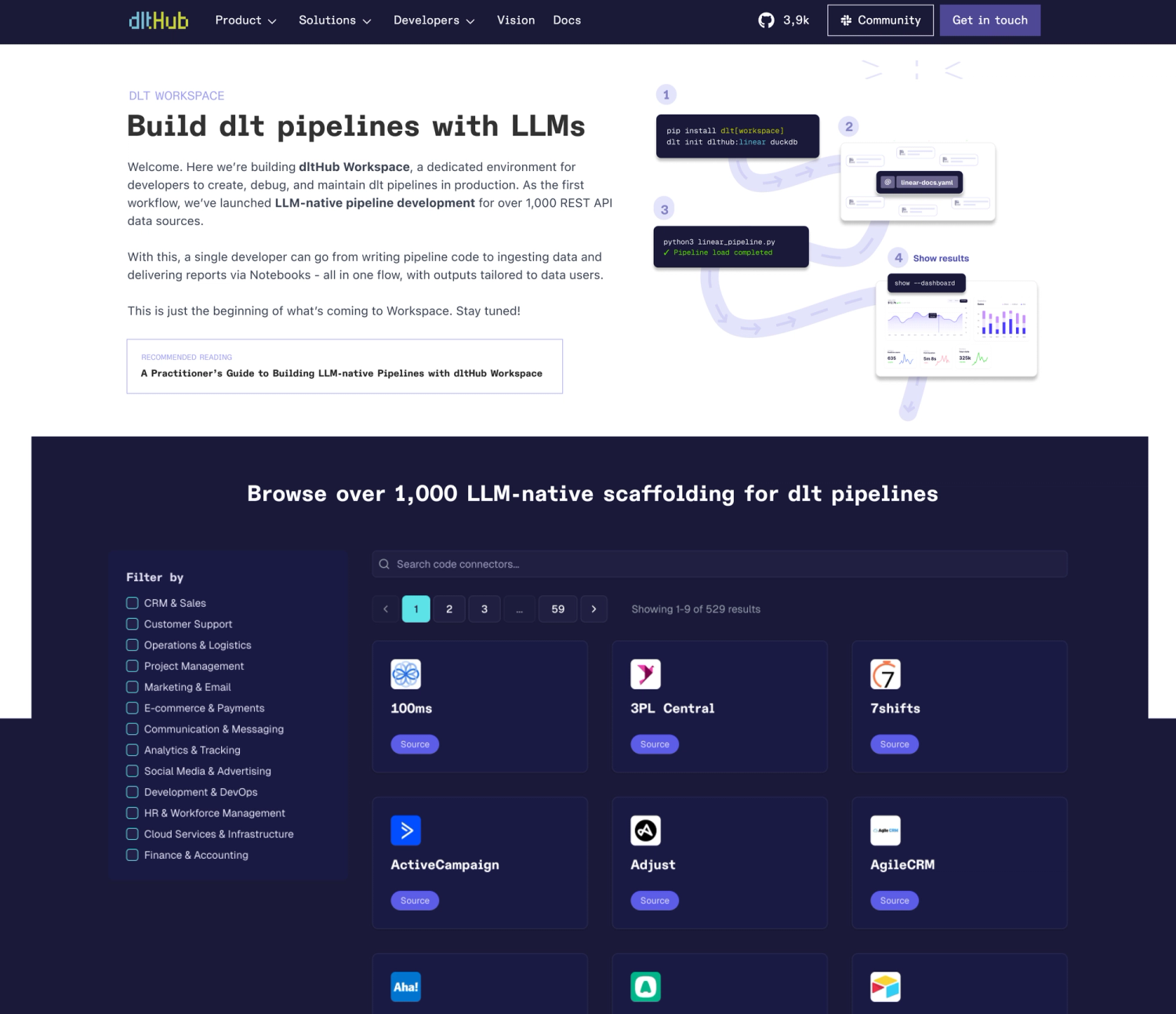
Challenge: Creating and maintaining reliable data pipelines has traditionally been the domain of experienced data professionals

Most data tooling assumes you have a team: infra engineers, DevOps, analysts, and someone to monitor pipelines when they break. But many developers - especially those building analytics into products or managing data as a side task - don’t have that setup.
A Python-native, LLM-first, and agentic data-engineering platform can remove today’s skill barrier and expand the pool of data-platform engineers from ≈100k specialists to the world’s over 21M Python developers. It can augment the productivity of solo data engineers.
Solution: Introducing dltHub, so that any Python developer can bring their business users closer to fresh, reliable data
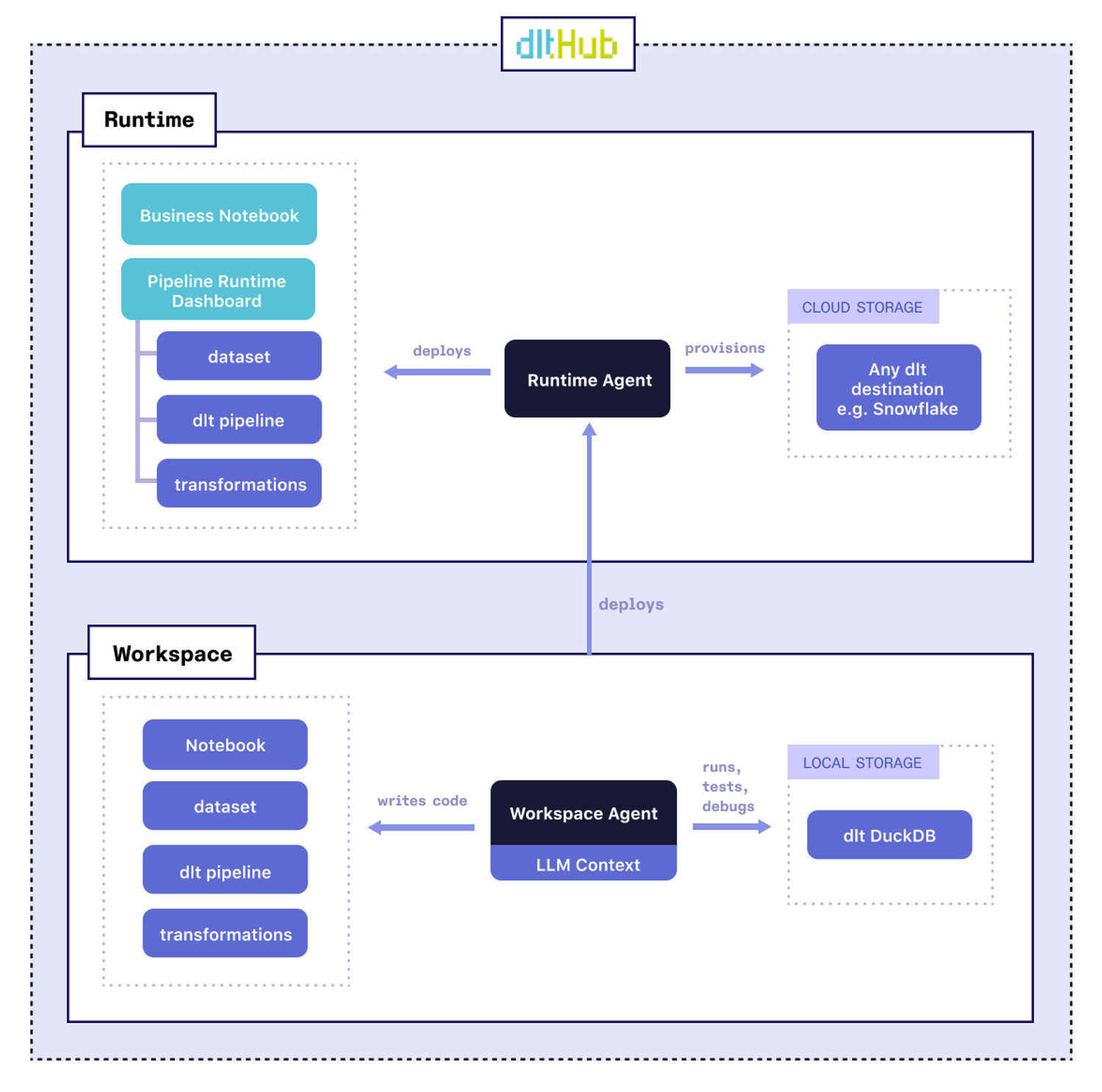
This is why we’re building dltHub. dltHub enables a single Python developer to do data engineering tasks that previously required a complete data team. dlt developers will be able to deploy and run anything that they built in their LLM-first dltHub Workspace - dlt pipelines, transformations, and Notebooks with a single command, and without the need to worry about infrastructure. The dltHub Runtime Agent, the highly customizable Runtime Pipeline Dashboard, and data validation tests will help them to maintain pipelines and data. Any Python developer will be able to handle tasks like data platform maintenance, pipeline customization, and data quality fixes. They will be able to provide their business users with fresh, reliable graphs, reports, and apps, without worrying about schema changes or silent pipeline failures.
Background: In the last two months, users have increasingly used LLMs to create dlt pipelines
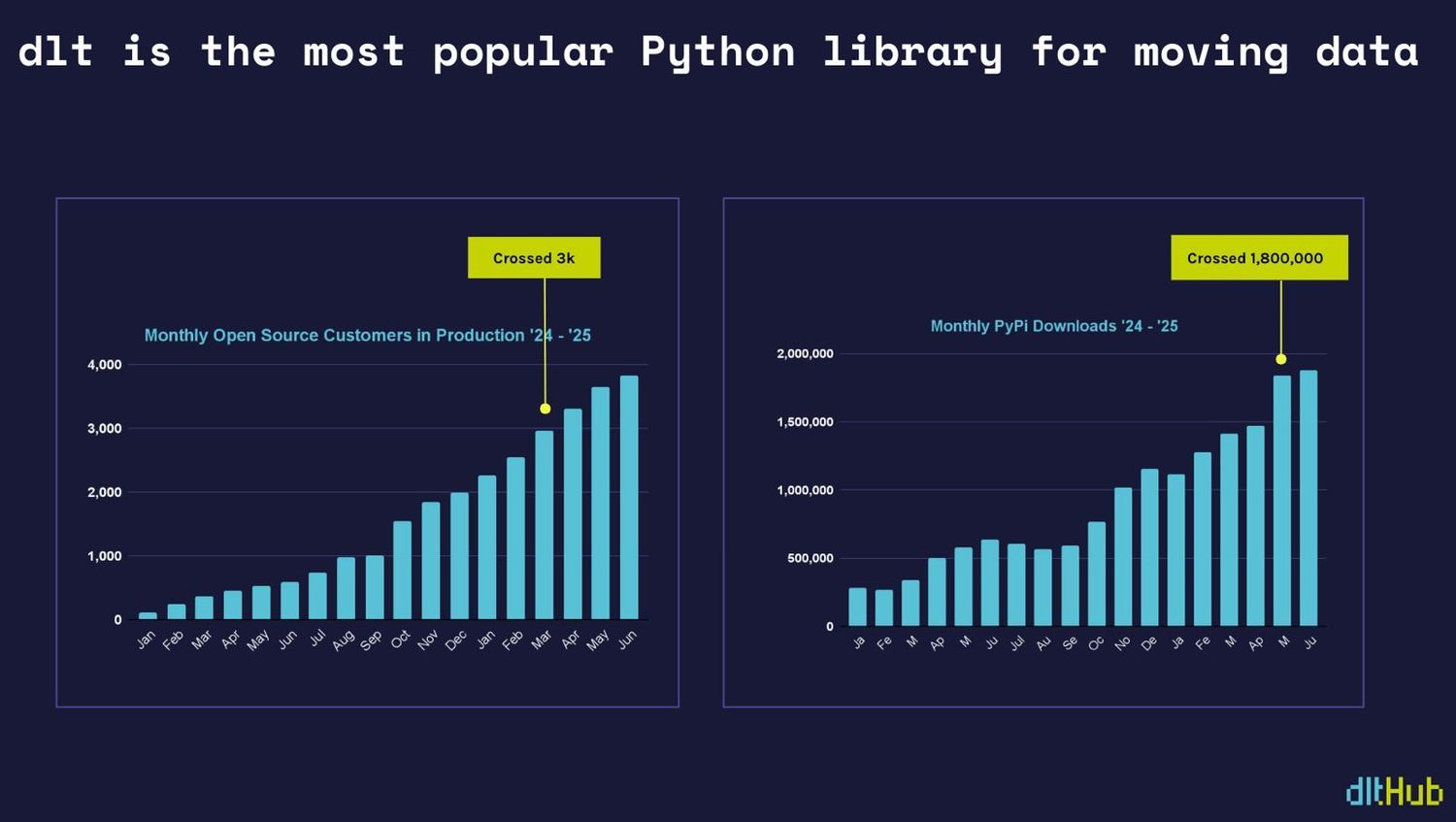
In the summer of 2022, we launched dlt based on a simple insight: while Python dominates AI, analytics, and data workflows, Python developers have been underserved when it comes to data tooling. There was no simple, straightforward, reliable tool for moving and organizing data. Today, dlt is the most widely used Python library for data movement.
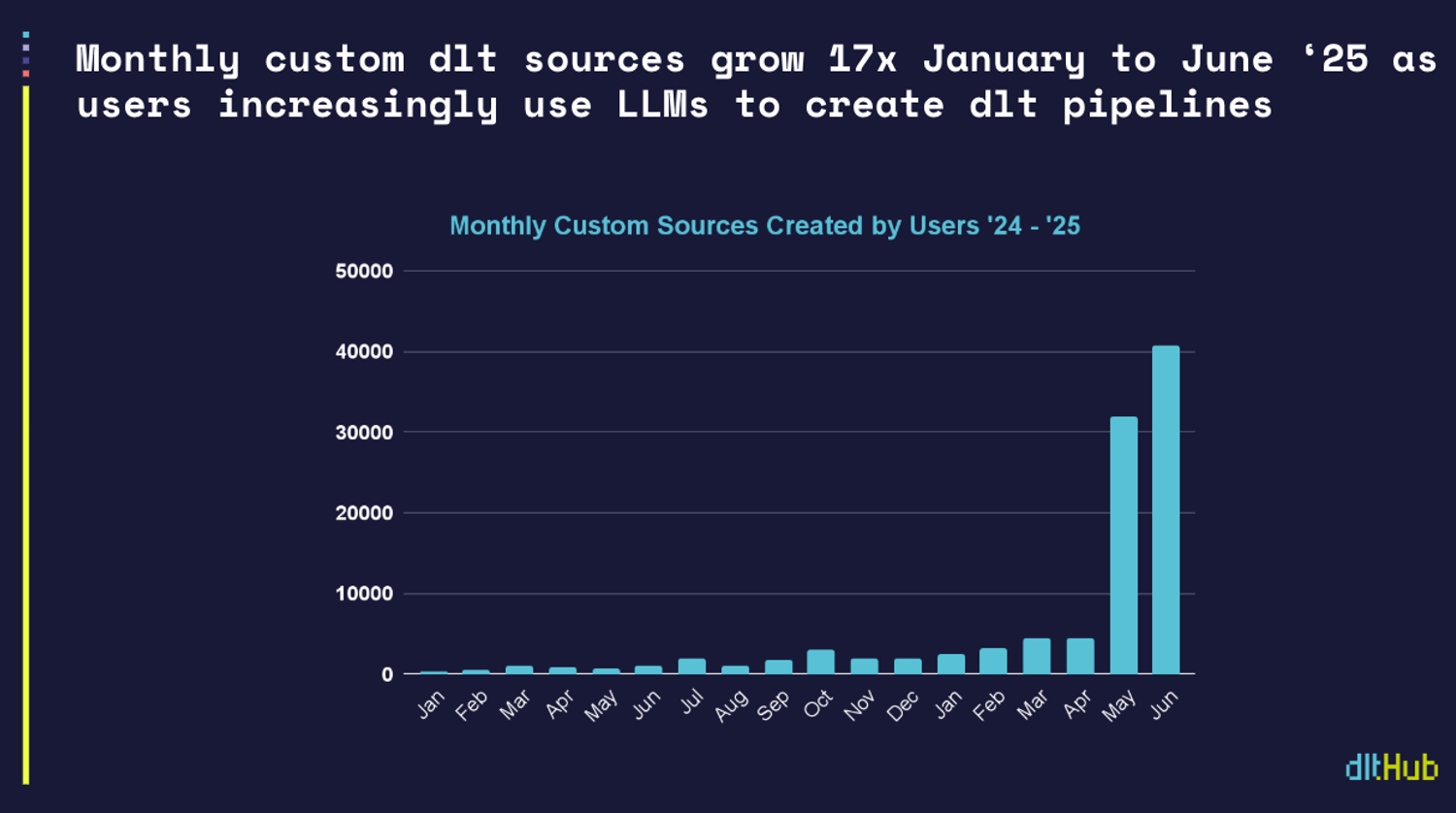
Since the inception of dlt, however, we've believed that its adoption by the next generation of Python users would depend on how well it integrates with code generation tools. From the very beginning, we’ve built dlt to be usable by both humans and large language models, with the conviction that this approach would significantly accelerate the process of writing data pipelines. In April, we noted a shift towards LLMs and released additional LLM tooling. In the last two months, LLM-native workflows have become dominant in how users create dlt pipelines. In June alone, the community created 40,757 custom dlt sources.
Why now: This is why we introduce LLM-native dlt pipeline development as the initial dltHub workflow
With LLM-native dlt pipeline development, a single developer is empowered to complete a data workflow from writing dlt pipeline code to ingesting data to Notebooks with reports that are useful for the end user of the data.
At the beginning, developers will be able to:
- grab the LLM-native scaffolding for dlt pipelines
- build a working pipeline in 10 min (initially using Cursor)
- and explore their data in our Workspace Notebook.
We’re releasing the dltHub Workspace with an initial set of Workspace features in General Availability:
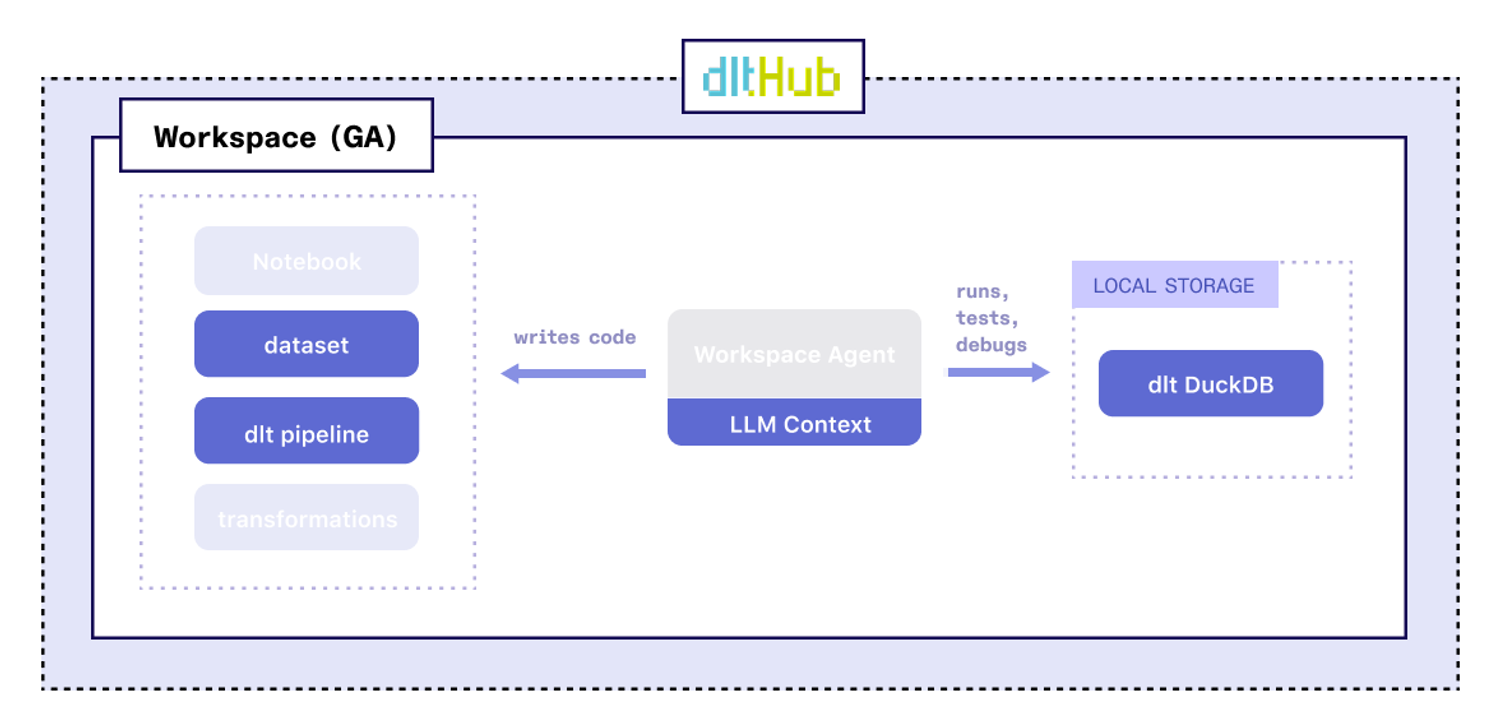
- An LLM Context database with scaffolding for 1,000+ REST API data sources, and an enhanced dlt init command that lets our users create dlt pipelines using the context
- An enhanced dlt dataset interface that enables developers to create reports and explore data much more quickly within a notebook environment. It also lays the groundwork for powerful data quality features, such as column-level lineage with annotation propagation
- A local dlt pipeline dashboard where users can quickly explore data, schemas, and debug pipelines.
We’re especially proud of our LLM-native scaffolding for dlt pipelines, what Andrej Karpathy refers to as Software 3.0. We see this as a powerful way to boost data engineer productivity, and we expect the number of available LLM contexts to grow quickly.
Roadmap
This is only the first of many Workspace releases. In the near future, for example, we plan to add a Workspace Agent that helps with coding tasks, debugging and testing a dlt pipeline pipeline.

The release of the dltHub Runtime Agent, the highly customizable Runtime Pipeline Dashboard and data validation tests is months away. dltHub Storage will be released in Q2 next year. dltHub Scale, aimed at SMBs, and dltHub Enterprise will follow later.
Demos
LLM-Native Development of an OpenAI API cost monitoring dlt pipeline
Watch how our AI engineer Thierry utilizes LLM context in dltHub Workspace to build a dlt pipeline that fetches OpenAI API cost data and loads them into DuckDB
Utilizing the Pipeline Dashboard for data debugging and the Notebook to create a report of weekly OpenAI API costs for an end user
Explore the initial features of dltHub Workspace with Thierry! Learn how the Workspace helps data engineers monitor pipelines, track schema changes, and quickly dive into their data for analysis and visualization.
✨ What’s inside:
- Pipeline Dashboard: Full visibility into your pipelines — track schema changes, columns, tables, and more. You can even explore this metadata in plain English thanks to MCP.
- Workspace Notebook: Instantly analyze data and build visualizations right in the Workspace. Watch Thierry create a report on OpenAI API costs, all in Python.
Please note that the demo uses some of the upcoming Workspace features such as MCP and dlt transformations. These are some of the early Workspace workflows that we are working on to augment the productivity of solo data engineers.