How dltHub consulting partner Mooncoon speeds up complex dlt pipeline development 2x with Cursor
AI + dlt = 2x faster pipelines. Mooncoon 🦝 shares how Cursor IDE transforms pipeline dev. AI handles boilerplate; you ship faster. Practical workflows & a live demo inside.
 Marcel Coetzee,
Marcel Coetzee,
Data and AI Plumber at Mooncoon, an analytics and data agency.
Introduction
Ready to supercharge your dlt pipeline development with AI? While we're still working toward fully autonomous data engineering, today's AI assistants are already incredible accelerators for building robust data pipelines. Combined with dlt's productivity features, AI can help you ship pipelines faster by handling routine tasks such as:
- boilerplate code,
- basic error handling and
- schema definitions.
We at Mooncoon think of AI code assistants as having an enthusiastic junior developer who never gets tired of the repetitive stuff.
What is AI-Driven Pipeline Development?
AI-Driven Pipeline Development is a methodology that integrates Large Language Models into the data pipeline development workflow through IDE extensions and specialized tools.
These AI assistants can potentially help with various aspects of dlt pipeline development, though their effectiveness depends heavily on your understanding of dlt's architecture and your ability to guide the AI with proper context and requirements.
When working with dlt, an AI assistant might help with tasks like suggesting schema contracts, implementing error handling patterns, or generating basic source configurations.
However, the quality of these suggestions relies entirely on your ability to validate them against dlt's best practices and architectural principles. Again, think of the AI as a junior developer who knows general Python patterns but needs your expertise with dlt's extract-normalize-load workflow to produce production-ready code.
I believe this process, from Anthropic, perfectly captures the natural flow between developers and their AI-enabled IDE.

Setting Up an AI-Driven dlt IDE
We use Cursor for this post, but you could just as well have used any other IDE with strong LLM integration, like Zed or Windsurf with similar success.
Configuration and Settings
Getting your Cursor IDE configured properly for dlt development isn't just about checking a few boxes - it's about creating an environment where your AI assistant can truly understand your pipeline architecture and provide meaningful assistance. A well-configured setup means the difference between getting generic Python suggestions and receiving contextually aware recommendations.
Set the LLM Provider and Context Length
You can set this in the "Models" Tab in settings. I recommend using Claude 3.5 Sonnet with its long context window to fit as much dlt documentation and code in as possible. Also enable long context chat if your LLM has long enough context, so you can use dlt documentation as context:

Ignore Irrelevant Files
The key is optimizing how Cursor indexes and understands your dlt codebase. Start by ensuring your .cursorignore file excludes test data, cached pipeline runs, and other non-essential files that could dilute the AI's understanding of your core pipeline logic. Here's what a .cursorignore might look like:
.dlt/secrets.toml
.ipynb_checkpoints
.venv/Notice that we don't send secrets to the providers in the interest of security. We however do want to send the .dlt/confg.toml as it contains valuable configuration the LLM might use.
Design and Set the System Prompt
Create a .cursorrules file in your project root to provide specific guidance to the AI assistant about dlt conventions and best practices. This ensures all suggestions align with dlt's architectural principles.
Crafting an effective system prompt is crucial.
The Anthropic prompt engineering tutorial provides valuable techniques that can be applied here. Consider these key practices:
- Assign the AI a role, for example, "You are a data engineering expert"
- Use in-context learning, such as chain-of-thought prompting
- Be specific in what you want
Here's an example of what your .cursorrules file might look like:
# DLT Assistant Prompt
You are an expert AI assistant specializing in helping beginners
create reliable data pipelines using the dlt (data load tool)
framework. Your primary goal is to provide clear, comprehensive
guidance for building effective data pipelines, with a focus on
immediate feedback and data verification.
When responding to queries, always analyze the request using
<pipeline_analysis> tags to show your thinking process.
…You can find the complete version of this prompt in the repository's .cursorrules. Try using it in your dlt pipeline development process to see whether you get any gains.
Maintaining the system prompt in a file, rather than configuring it through the UI, offers several advantages: it's more maintainable, version-controllable, and easily shareable amongst team members.
To enable this feature, select the "Include .cursorrules file" option in the settings menu after you have navigated to Cursor Settings > General > Rules for AI.

Add Your Knowledge Base
Index the dlt documentation by going to Cursor Settings > Features > Codebase indexing and adding the link to dlt docs: https://dlthub.com/docs.
This allows Cursor to understand dlt's concepts, best practices, and API details when providing suggestions. The indexing process takes a few minutes as Cursor analyzes the documentation content.
When it comes to your dlt codebase itself, you'll want to enable codebase indexing in the same settings panel. This creates embeddings of your pipeline code that help the AI understand your specific implementation. The process runs automatically in the background, and your index will stay synchronized with your latest changes.
The indexing process analyzes the documentation content and makes it available as context for the AI interactions.

The Workflow
As mentioned earlier in this post, I think Anthropic's agentic workflow with human-in-the-loop describes the data engineer / AI interaction quite well.
The key is maintaining a natural dialogue between developer and AI assistant, where the human guides the process while the AI handles routine implementation details. Here's how this workflow adapts to dlt pipeline development in Cursor:
In practice, I'll lay out this flow as applied to cursor:
1. Start by opening the chat modal (Ctrl/⌘ + L) and describing your intent in detail. The key here is specificity — help the AI understand not just what you want to do, but why you're doing it. This context helps generate more relevant solutions.
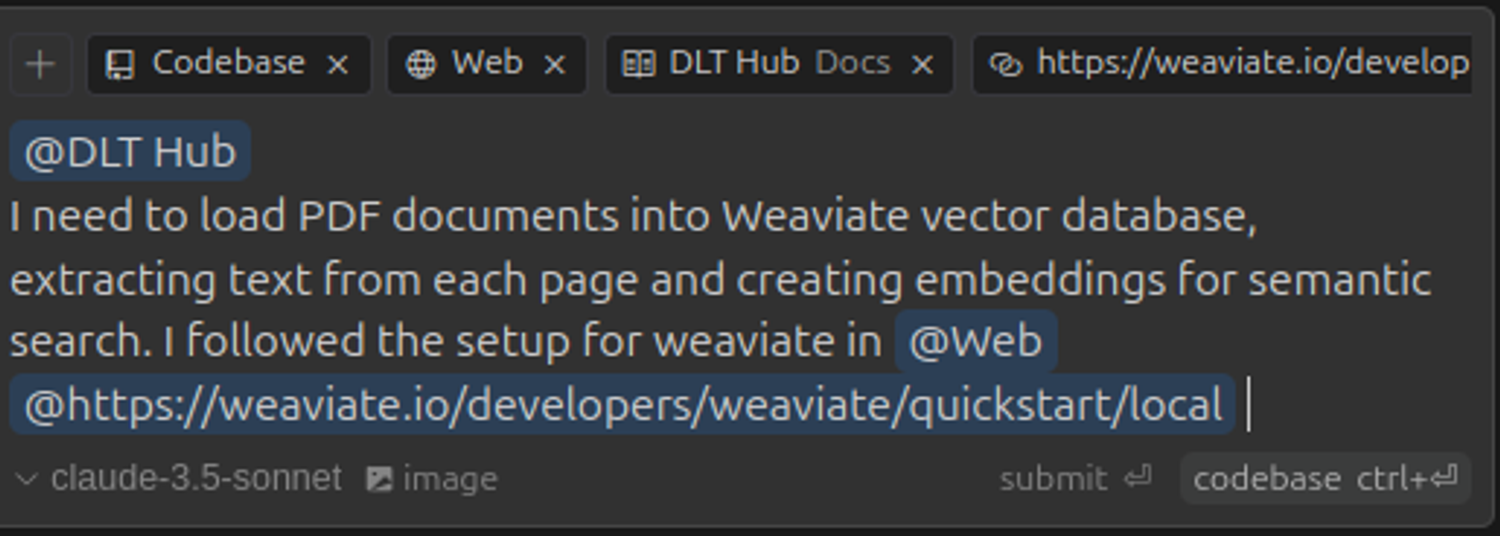
2. Before sending your query, enrich it with relevant documentation using the @Docs symbol. For dlt specifically, you'll want to include the framework documentation to ensure the AI understands the architectural patterns and best practices. You can also add links to associated documentation with the @Web symbol, for example, here I added the link to the Weaviate setup I used so the LLM knows how to advise me to setup dlt configuration.
3. While Cursor's embedding search works well for smaller projects, dlt's complexity benefits from a more thorough analysis. Use the @codebase command with "smart" reranking and reasoning enabled to get more contextually aware responses:
4. Initiate the RAG pipeline with ctrl+⏎ to get the AI's response. Cursor presents the solution in executable Markdown blocks that you can either run directly or apply to specific files.
And what is really important for us it provides the Python script with dlt source definition and dlt pipeline:
import os
import dlt
from dlt.destinations.adapters import weaviate_adapter
from PyPDF2 import PdfReader
@dlt.resource(selected=False)
def list_files(folder_path: str):
folder_path = os.path.abspath(folder_path)
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
yield {
"file_name": filename,
"file_path": file_path,
"mtime": os.path.getmtime(file_path),
}
@dlt.transformer(primary_key="page_id", write_disposition="merge")
def pdf_to_text(file_item, separate_pages: bool = False):
if not separate_pages:
raise NotImplementedError()
# extract data from PDF page by page
reader = PdfReader(file_item["file_path"])
for page_no in range(len(reader.pages)):
# add page content to file item
page_item = dict(file_item)
page_item["text"] = reader.pages[page_no].extract_text()
page_item["page_id"] = file_item["file_name"] + "_" + str(page_no)
yield page_item
if __name__ == "__main__":
pipeline = dlt.pipeline(pipeline_name="pdf_to_text", destination="weaviate")
# this constructs a simple pipeline that:
# (1) reads files from "pdfs" folder
# (2) filters only those ending with ".pdf"
# (3) sends them to pdf_to_text transformer with pipe (|) operator
pdf_pipeline = list_files("pdfs").add_filter(
lambda item: item["file_name"].endswith(".pdf")
) | pdf_to_text(separate_pages=True)
# set the name of the destination table to receive pages
pdf_pipeline.table_name = "PDFText"
# use weaviate_adapter to tell destination to vectorize "text" column
load_info = pipeline.run(weaviate_adapter(pdf_pipeline, vectorize="text"))
print("Load info:", load_info)
# Query the results
import weaviate
client = weaviate.Client("http://localhost:8080")
result = client.query.get("PDFText", ["text", "file_name", "mtime", "page_id"]).do()
print("\nLoaded documents:", result)Now, all you need to do is run the script:
This pipeline actually worked first time! You can find the generated script here. If you’d like to run the completely AI generated pipeline for yourself you’ll need to:
- Install the dependencies with pip install -r requirements.txt
- Start a local Weaviate instance along with Ollama:
ollama pull nomic-embed-textollama pull llama3.2docker-compose up -d(I did put the compose file in the project root for your convenience)
- Run the pipeline with
python pdf_pipeline.py
Debugging
I didn’t encounter errors in this run, but If you do encounter errors, don't waste time going down rabbit holes. Instead, use the "Debug with AI" feature for quick fixes of simple issues. For more complex problems, click "Add to Chat" to maintain the full context of your development session:

General recommendations
Keep your iterations small and focused. If the pipeline isn't working as expected, use the inline AI chat (Cmd K) to make targeted adjustments. Remember to communicate what hasn't worked in previous attempts - this helps the AI avoid suggesting solutions you've already tried.
When a piece of functionality is working correctly, commit your changes and start the next cycle. This Short-Lived Feature Branch workflow helps contain tasks and makes it easier to revert any problematic AI suggestions. Think of each iteration as an experiment: you're gradually building up working functionality while maintaining the ability to step back if needed.
The key to productive AI-assisted development is maintaining momentum while staying on track. Keep your iterations small, your feedback specific, and don't hesitate to start fresh if you find yourself going in circles.
Final Thoughts
AI assistants like Cursor can meaningfully speed up dlt pipeline development by handling routine implementation details, allowing developers to focus on architectural decisions and data modeling. The quick iteration cycles enabled by AI-assisted coding are particularly valuable when building complex, multi-resource pipelines where quick experimentation helps validate different approaches.
However, the practical value of AI coding tools evolves rapidly, and what works today may be superseded tomorrow. It's worth periodically re-evaluating your AI toolchain every few months to ensure it genuinely enhances your workflow. Most importantly, remember: don't outsource your critical thinking to machines. AI should complement your expertise as a data engineer, not replace your judgment.
Next steps
- Check out the .cursorrules: https://github.com/dlt-hub/cursor-demo/blob/main/.cursorrules and discover the magic behind the scenes.
- Don’t miss your chance to join the dlt+ waiting list https://info.dlthub.com/waiting-list , sign up now to get exclusive updates on our cutting-edge AI agents and protocols designed to streamline data workflows with dlt.
- Got questions about integrating AI into your processes? Contact our Solutions Engineering team https://dlthub.com/contact for expert insights and best practices tailored to your needs!