Surviving the AI code Deluge: Data quality in the Spotlight
This is, we’re told, the great democratization of data engineering. The tedious work is gone. The barrier to entry is gone. Everyone can now be a data engineer.
 Adrian Brudaru,
Adrian Brudaru,
Co-Founder & CDO
Our AI-Powered Interns
The demo is magical. You feed an arcane API document to an assistant, and a few seconds later, a hundred lines of functional Python appear. The code runs. It’s the culmination of a decade-long obsession with velocity. We wanted to build pipelines more quickly, and now the machine builds them for us. It feels like the future.
This is, we’re told, the great democratization of data engineering. The tedious work is gone. The barrier to entry is gone. Everyone can now be a data engineer.
Footguns ahead!
And yet, I can’t shake the feeling that we’re just handing out footguns at a firing range. For all our technical progress, the culture of the data profession remains stuck in a “YOLO” era. Unlike software engineering, which collectively decided decades ago that shipping untested code to production was a professional malpractice, data teams do it every day. We merge to main, run the job, and pray. Our primary safety feature is a stakeholder screaming when a dashboard looks wrong and the developer who does their best job to test during development and create hopefully-bug-free code.
Into this world of just winging it, we’ve now introduced an army of infinitely productive, fantastically naive, AI-powered interns. They can write code faster than any senior engineer, but they have zero context, zero judgment, and no idea what the data they’re moving is actually for. They are self inconsistent in what they create. a true force multiplier for our worst habits.
While a developer might test as they code, LLMs code might be completely unhinged and autofill based.
However the problem isn't that the intern writes bad code. The problem is that it forces us to confront what our jobs actually are.
Separating busy work from leverage
Ask yourself: when was the last time your CTO shipped a production feature? The answer is likely never. A senior technical leader’s value isn’t in their direct output; it’s in their leverage. A junior engineer ships a feature. A principal engineer ships a system that allows ten other engineers to ship features safely. A CTO creates an environment where the entire organization can. The higher you go, the more your work is about building the factory, not pulling the lever.
For too long, the data world has been caught in a leverage trap. Our most senior people are still celebrated for parachuting in to write a heroic, last-minute SQL query to fix a broken report. It feels impactful, but it’s a trap. It builds no lasting system, no durable advantage. It is the work of a craftsman, not an architect.
The AI intern automates the craftsman’s work into oblivion. It can produce more handcrafted pipelines in an afternoon than a human can in a month. It can write the heroic SQL query in seconds. The intern is not coming for your job; it's coming for the low-leverage parts of your job, and in doing so, it’s exposing what the real work should have been all along.
This is the promotion we've been offered. The choice is no longer between writing code and writing it faster. The choice is to stop being the heroic craftsman and to finally become the manager.
The manager’s job is not to write the pipeline. It is to ask, “Do I trust the data coming out of it?” Their work is to cultivate a healthy paranoia. Their output isn't a dashboard; it's a set of standards, a culture of verification, and the boring, essential infrastructure of trust. It’s the work of a governor, designing a system of checks and balances for a productive but naive new populace.
The AI intern is here, and it's asking for its onboarding packet. It needs to know the rules of the road, the definition of "good," and the consequences for failure. It is waiting for a manager to tell it what to do and place it into a structure where they will be successful.
The Burden of Proof increases and new approaches are needed
Think about how a human writes code. It’s not a single act of transcription; it's a tight, iterative loop of thought and verification. You write a few lines, you pause, you re-read them. You run a small piece of it. You taste the sauce as you're cooking. This constant, internal dialogue and inherent skepticism is the invisible, continuous testing that separates good code from a pile of sh…yntax. The human programmer is a deeply untrusting author.
An LLM does not do this.
It performs a monologue. It generates a monolithic block of text that is, frankly, a small miracle if it runs at all. It hasn't been tested. It hasn't been reconsidered. It often contains bizarrely verbose and self-contradictory passages where it writes some nonsense and then writes more code to undo the nonsense, because it lacks the human's internal editor.
The correctness of the output is anyone's guess.
This changes everything for the human manager. Your starting assumption cannot be, "This code might have bugs." Your assumption must be, "This code has all the bugs." The burden of proof has shifted entirely onto you. Your job is no longer creation; it's a forensic audit. You are now spending significantly more of your time on validation.
Will you assist the AI, or will you direct it?
It’s 10 AM on a Thursday, and you’re staring at a dashboard that’s wrong. The pipeline that feeds it was generated by an LLM. The code looks plausible. It runs without errors, but the final number is off.
This is the moment. This is the crucible where you either become an entity cruncher for life or you have a career-altering realization.
The cruncher asks, “How can I find the bug in this 200-line script?” They accept the premise, dive into the code, and spend the next three hours in a painful, manual grind. They are doing the Zero Theorem work.
The manager, in that same moment of frustration, asks a different and far more powerful question:
“Why am I debugging a 300-line script in the first place?”
This is the pivotal insight. The problem isn’t the bug; the problem is that you’ve created a system that allows for these kinds of bugs to exist. You've asked an AI intern to write a complex, free-form essay, and now you’re surprised it has grammatical errors. The only way to win is to change the game.
The answer isn’t to get better at debugging the essay. The answer is to stop asking for one in the first place.
Our fundamental belief is that the only sane way to work with LLMs is to aggressively constrain the problem. Instead of asking an LLM to perform the complex, open-ended task of writing an imperative pipeline, dlt asks it to perform the simple, constrained task of filling out a declarative configuration. The output is no longer a 200-line script you have to audit; it’s a 10-line specification you can verify at a glance.
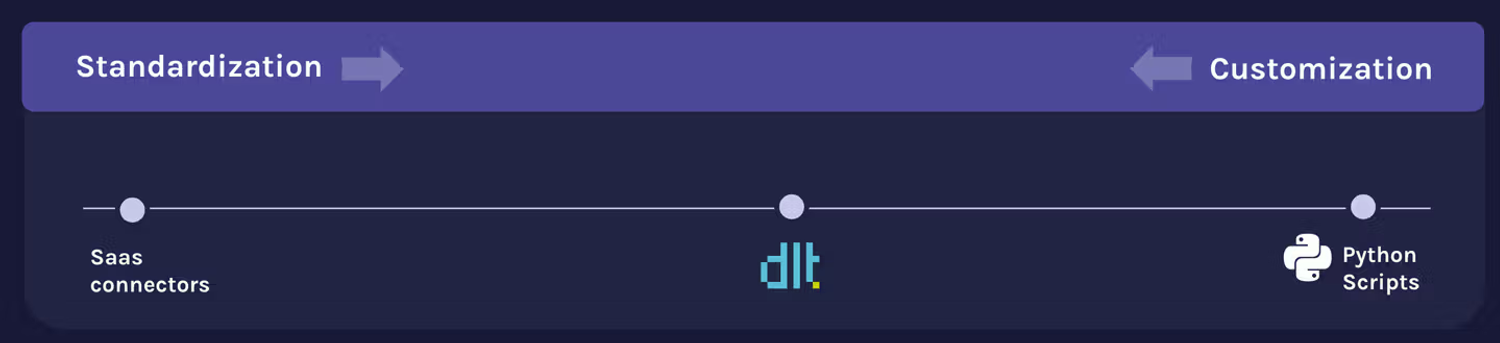
Code can still be added for customisation. This enables us to keep the best of both worlds - declarative low-code where possible, imperative full code where needed.
We’ve turned an impossible validation problem into a trivial one.
Read more about how dlt constrains the problem of code generation into short, reviewable configuration.
Less code less problems, what about the data?
But even with a perfect configuration, the source data can be a mess. This is the second part of the job: not just validating the intern’s instructions, but interrogating the work it produces. That’s why we’re improving our pipeline dashboard debugging app on top of this foundation. It’s a workbench for the skeptical developer. It allows you to run the pipeline in a safe, isolated sandbox and put the resulting data under a microscope.
To be efficient, we are looking at a tiered approach
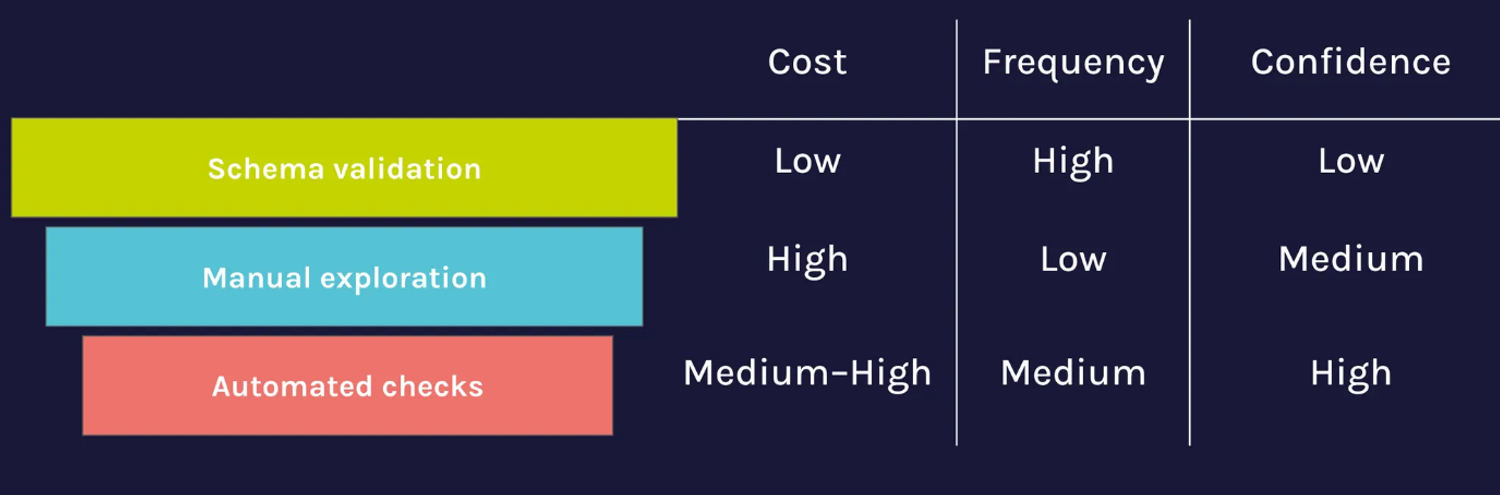
- Schema Validation: Validate schemas and manage drift automatically with schema evolution or data contracts (in dlt)
- Manual exploration: Validate the pipeline is transporting data correctly. Validate assumptions you will make in using or modelling this data (in dlthub workspace)
- Automated checks: Finally, turn those assumptions into always-running tests that ensure that the assumptions you base your downstream work remain the same over time. (Coming soon in dlthub Runtime)
Our AI-native, human-sanity centric Workspace workflow
As we mentioned before, we moved from ai-assistance to ai native, leveraging AI in multiple parts of the development workflow, as you can see below.
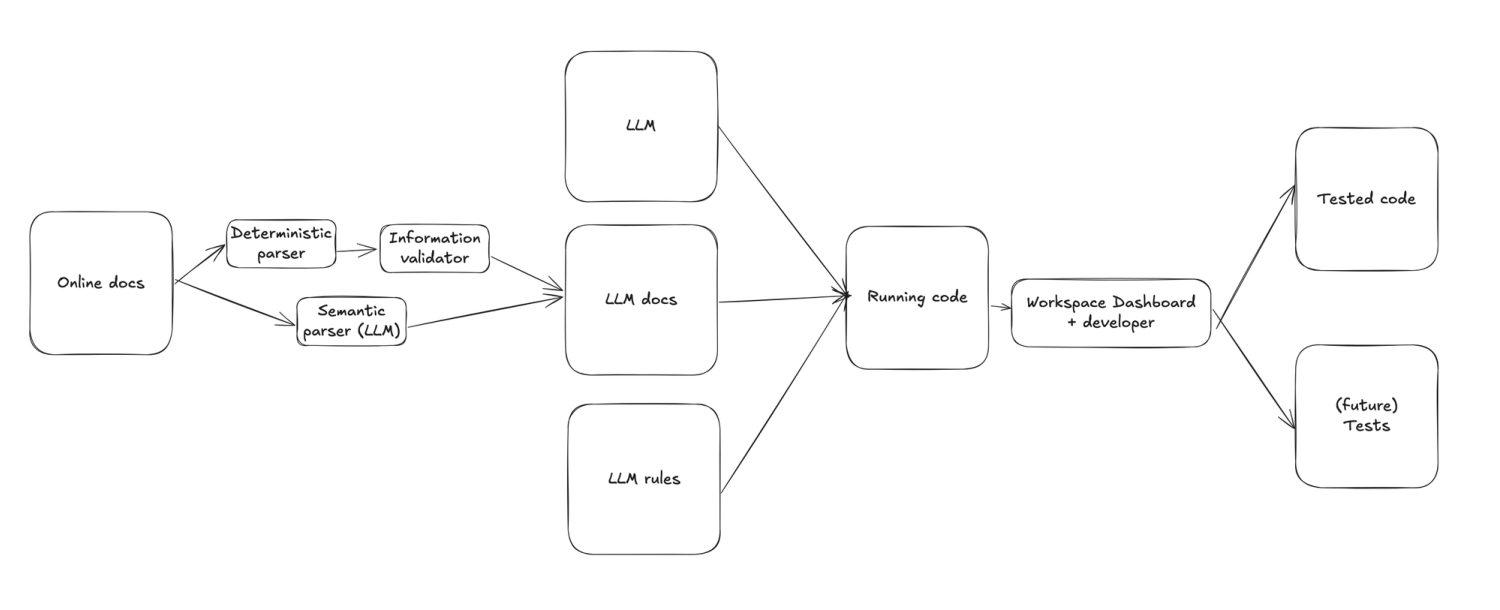
In the above diagram you can see how we use a number of methods to extract and validate information from online docs before giving it to a machine together with more instructions, to generate the code to the level that it runs. Beyond that, validation happens by the human in the workspace app. In the future, users will be able to create tests, run them and later deploy them via this app.
We previously did not communicate much about this workflow because we wanted to improve the quality of the LLM contexts. Now, with a combination of verified information, and pointers to original docs the scaffolds perform much better than just indexing the online docs in your IDE and combining it with our rules.
Try it today!
Like it? hate it? missing something? let us know!
Already a dlt user?
Try dltHub free for 14 days, $30 in credits included.