dltHub Transformations: what Claude/Codex/Cursor need to model your business
In public preview today as part of dltHub. dltHub Transformations turns raw data into the clean tables your business and your agents actually use. Built for a moment when agents now write 9 out of 10 data pipelines.
 Matthaus Krzykowski,
Matthaus Krzykowski,
Co-Founder & CEO
On this page
- Data work that needed a team is moving to one person and an agent. The quarter you budgeted for a data migration is moving to two weeks.
- Pipelines just exploded, and the old transformation layer can’t keep up
- Tools move data. They don’t move context.
- Part 1. The engine: @dlt.hub.transformation
- Part 2. The dltHub transformation toolkit (how you use it in Claude, Codex, or Cursor)
- 1. /annotate-sources produces taxonomy.json
- 2. /create-ontology produces ontology.json
- 3. /generate-cdm produces CDM.dbml
- 4. /create-transformation produces @dlt.hub.transformation Python code
- Try dltHub
Today we’re announcing that dltHub Transformations is in public preview as part of dltHub. Full reference in the Transformation docs.
It ships with the dltHub transformations toolkit, a step-by-step workflow for Claude, Codex, or Cursor that writes those tables for you. You describe your business, the toolkit writes the code, the dltHub transformation engine runs it.
This post is the short version. First, what’s changing for the people who actually do data work. Then why it’s changing now. Then how the thing works, and what our customers are doing with it. For a more in-depth explainer to the practitioner, read my co-founder Adrian’s post: One runtime, one agentic context, end to end with dltHub Transformations.

Data work that needed a team is moving to one person and an agent. The quarter you budgeted for a data migration is moving to two weeks.
If you’ve ever waited months on a data team for an answer about your own business, or if you’ve been the data team trying to keep up, dltHub Transformation is for you.
It’s also for the person who’s been asked to approve hiring three more data engineers, or paying a consultancy six months to model your data. Both of those decisions look different now.
We’ve been giving Transformations to early-access partners and running it in production for months. Three patterns keep showing up.
Migrations that needed a quarter and a hiring round are now done in weeks and can be handled by the team our partners already have.
Navit is a ~20-person Berlin-based corporate mobility platform. Their first-generation platform had drifted. SLA in the 80s, the definitions of “account” and “deal” lived partly in one contributor’s head. When this type of issues occurs, the standard answer is to hire three senior data people and plan work for six to twelve months. Instead, Navit’s team brought in dltHub Forward Deployed Engineers and ran the transformation toolkit against the existing pipelines. Three weeks later: the ontology, the canonical model, the new transformation layer, and Chat-BI were all in place. SLA went to 99%+. Time-to-new-metric dropped from days to hours. A single generalist on Navit’s team now maintains the stack, there are no new hires.

We did the same thing to ourselves: we migrated our own CRM from HubSpot to Attio in two weeks, with one working student and Claude Code. This is work our industry budgets a quarter for and assumes that can only be done by senior engineers.
The most expensive piece of consulting work, modeling, is being productized. Tasman Analytics, a 20-person Amsterdam-and-London consultancy that sells fractional data teams, saw it coming in January when it started using a very early version of dltHub before our transformation toolkit existed:
“The data modeling layer is where the real cost lives, and it’s where consulting companies like ours have been doing the most repetitive, high-cost manual work. We are excited about the dltHub product vision for agentic transformation because the main challenge in all data projects is how the data is being interpreted.”
Thomas in’t Veld, CEO, Tasman Analytics
Thomas was articulating the vision then. Now it is in Public Preview. Tasman can now price fixed-price work where they used to price time-and-materials, and their clients get the modeling work built in.
Mid-level engineers are doing what senior engineers used to do. Tasman’s staff engineer Marcello Victorino:
“A mid-level engineer can spin up a prototype, browse the raw data, validate the SQL schema, all without pulling in a senior. That loop of prototype, inspect, fix, re-run, that’s the real unlock.”
Marcello Victorino, Staff Data Engineer, Tasman Analytics
What these examples share isn’t just the speed. It’s who’s actually doing the work, and what the work costs. Navit didn’t hire. Tasman can price fixed-price work where they used to price time-and-materials. We migrated our own CRM with a working student. People and budgets that, a year ago, would have been waiting on someone else.
The dltHub Transformation module has been built for over a year. The agentic workflow on top of it, the part that puts it in the hands of someone who doesn’t carry a “senior data engineer” title, is what we shipped over the last few months. Real engineering on both halves, and I’m proud of the dltHub team for shipping both.
Pipelines just exploded, and the old transformation layer can’t keep up
A year ago, agents wrote about 5% of the pipelines our community runs. Today they write 91%. The total number of community pipelines we see has gone from 2,400 a month to 81,000 (34x in a year). Local development on DuckDB, the prosumer base running pipelines on a laptop before they ever touch a warehouse, is 15x bigger than it was a year ago.
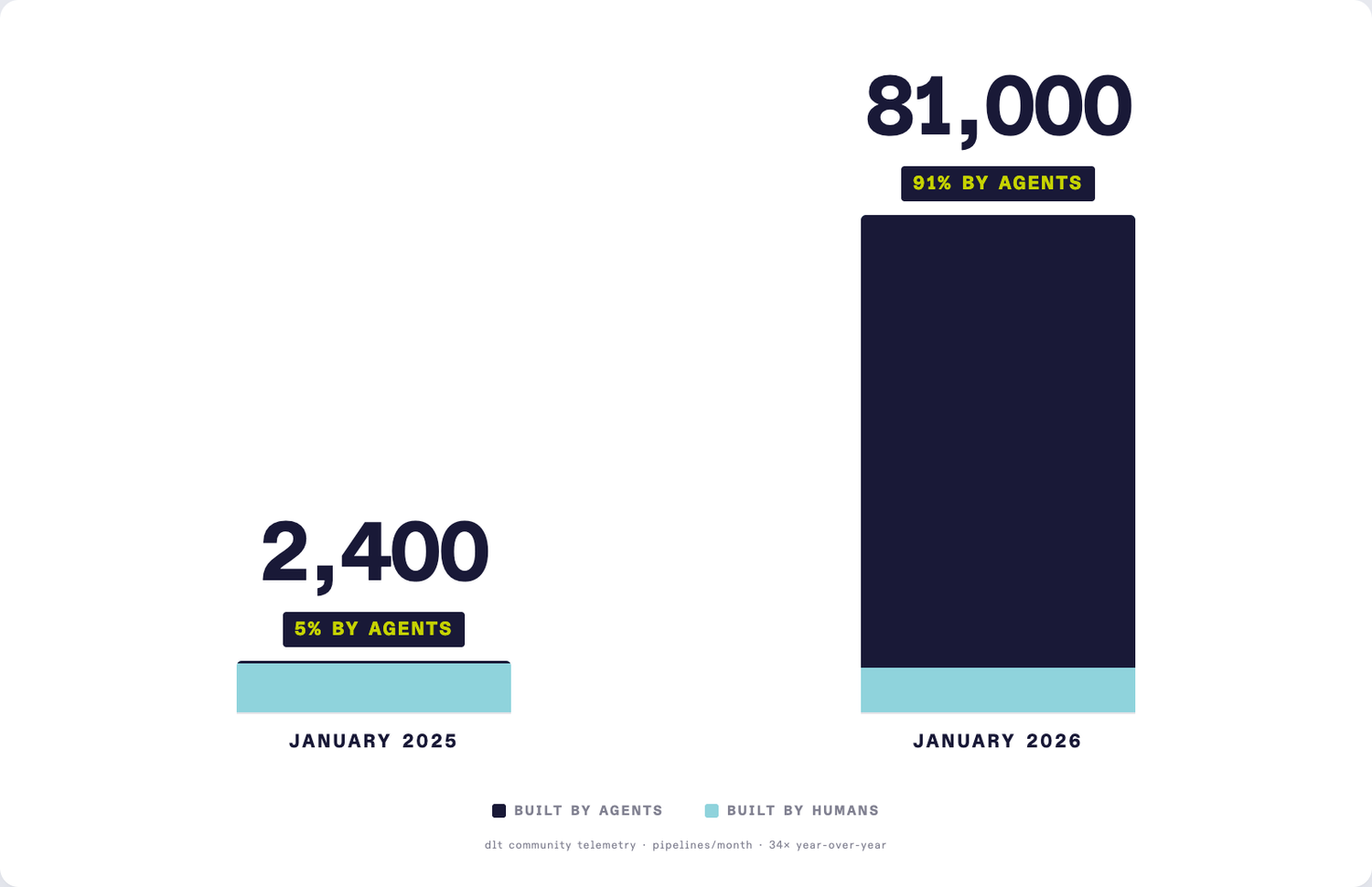
That’s not a feature trend. That’s the shape of data engineering changing. When pipelines were rare and expensive, the bottleneck was ingestion. When pipelines are cheap and agents write most of them, the bottleneck moves to the layer above: turning a firehose of new and constantly-changing sources into a clean, consistent model the business can actually read.
The transformation tools the industry leaned on for the last decade were built for humans writing pipelines slowly. Connectors fixed at build time. Models that break when columns change. Runtime gated behind a SaaS. They were never going to keep up with agents spinning up pipelines by the thousand. The world that’s now arriving needs a new kind of transformation layer: Pythonic, schema-aware, running wherever the developer (or the agent) is.
Tools move data. They don’t move context.
The deeper problem under the pipeline boom isn’t volume. As my co-founder Adrian says it’s that meaning gets stripped at every boundary in today’s stack. Schema knowledge stays at ingest. Join structure stays in transform. Lineage stays in the orchestrator. Runtime state stays in the warehouse. By the time the agent shows up, the context it needs to reason about your business has been thrown away three steps ago.
dltHub Transformation closes that gap. It produces the data model and the business context in one motion, from the same Python process that ingested the data, and exposes both to the agent for reasoning.
That’s not what a SQL editor with AI autocomplete does. That’s not what a chatbot bolted onto your warehouse does. This is the missing engine, the one that turns “agents can write SQL” into “agents can reason about your business.”
Part 1. The engine: @dlt.hub.transformation
dltHub Transformation is one Python decorator: @dlt.hub.transformation. You (or your agent) write a Python function that yields an Ibis expression or a SQL string. dlt compiles it to the right SQL dialect, executes it inside the warehouse, propagates schema and lineage hints, and updates the destination atomically. No data has to round-trip through Python memory.
import dlt
import ibis
@dlt.hub.transformation(name="orders_cdm")
def transform_orders(raw_orders: ibis.Table) -> ibis.Expr:
"""Example dltHub Transformation that builds a canonical orders table."""
# Simple example: filter, derive a few fields, and select canonical columns
enriched = (
raw_orders
.filter(raw_orders["status"] == "completed")
.mutate(
order_date=raw_orders["created_at"].cast("timestamp"),
order_total=raw_orders["subtotal"] + raw_orders["tax"] + raw_orders["shipping"],
)
.select(
"order_id",
"customer_id",
"order_date",
"order_total",
"currency",
)
)
return enriched

Wes McKinney, creator of pandas, founder of Ibis and Voltron Data
The same code runs on DuckDB, Snowflake, BigQuery, Postgres, or any of our supported destinations without a rewrite. Develop locally on DuckDB. Deploy to your warehouse. No translation step. Full reference in the Transformation docs.
That’s the engine. Now the part most people will actually touch.
Part 2. The dltHub transformation toolkit (how you use it in Claude, Codex, or Cursor)
Most teams will never write a @dlt.hub.transformation function by hand. They’ll work with the dltHub transformation toolkit, a set of skills you run from your editor with Claude, Codex, or Cursor. Each one is a slash command. Each one produces a file your team can read, review, and ship.
The toolkit’s job is to turn your raw data and your business knowledge into the Python code the engine runs. The path is taxonomy, ontology, CDM, transformations. In plain English: from “here are some database rows” to “here’s a map of your business, and the code that builds it.”
1. /annotate-sources produces taxonomy.json
We map your source tables (Shopify, HubSpot, Postgres, whatever) to the business concepts they actually represent. A “customer” in Shopify and a “guest” in your event platform are the same business concept. The toolkit proposes the mapping. You confirm or fix it.

2. /create-ontology produces ontology.json
For each business concept, the LLM establishes how it relates to the others. A Customer places Orders, an Order has Line Items, a Product appears in many Orders. A human confirms or fixes each relationship. The result is a map of how your business actually works, written in a format both you and a machine can read.

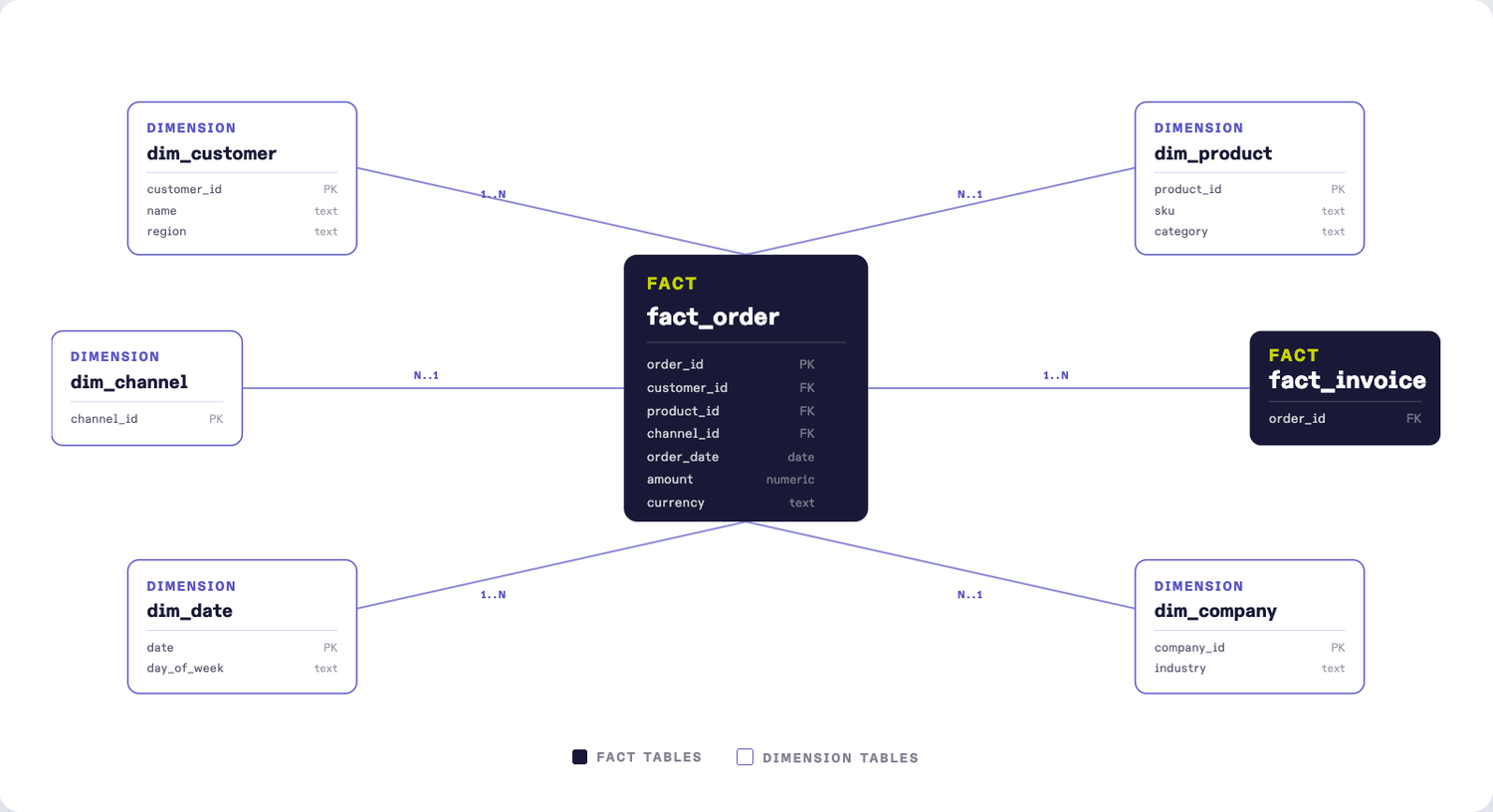
3. /generate-cdm produces CDM.dbml
From the ontology, we generate the code that creates a map of your business, typically 5 to 20 tables and their relationships that capture the context of your business. These are the tables your reporting, your dashboards, and your agent all read from. One definition per concept, used everywhere.

4. /create-transformation produces @dlt.hub.transformation Python code
Finally, the toolkit writes the transformations themselves, the actual Python the engine runs. It uses the taxonomy, the ontology, and the CDM as inputs, and emits one @dlt.hub.transformation function per canonical entity. Runs locally against DuckDB first so you see every row before it touches production.
You read each artifact. You ship each artifact. The toolkit does the typing. The engine does the work.

Navit and our FDEs applied the transformation toolkit to the existing pipeline. We migrated our own CRM from HubSpot to Attio using exactly this toolkit. The toolkit handled extraction, mapping, mock data generation, and the @dlt.hub.transformation code. The humans handled judgment and review. Jack wrote the full playbook: HubSpot to Attio in two weeks.
These two cases sit at two ends of the same product. Navit shows what happens when you point the toolkit at a drifted production stack. The Attio migration shows what happens on a clean greenfield. Both finish in weeks, not quarters. Both ship with a versioned, agent-readable model the team owns.
Try dltHub
uvx dlthub-start
Then /annotate-sources in Claude Code, Codex, or Cursor. Public preview is live today.
- Docs: Transformations
- Adrian’s practitioner companion post: One runtime, one agentic context, end to end with dltHub Transformations
- Case study: dltHub migration services give Navit production-grade data and Chat-BI, without hiring
- Migration playbook: HubSpot to Attio in two weeks
We’d love your feedback while it’s in preview.