Autofilling the Boring Semantic Layer: From Sakila to Chat-BI with dltHub
 Adrian Brudaru,
Adrian Brudaru,
Co-Founder & CDO
1. The old semantic layer: Trapped inside tools
Every BI tool has a semantic layer—they just don't call it that. Looker has LookML. Tableau has data models. Power BI has DAX measures. Metabase has saved questions and models.
These semantic layers do three things:
- Name mapping: Translate
c_id_09to "Customer" - Relationships: Define how tables join
- Metrics: Centralize formulas like "Revenue = sum(amount) - sum(refunds)"
The problem: these definitions are locked inside each tool. Your Looker LookML doesn't help your Python scripts. Your Tableau data model doesn't help your chatbot. Every interface reinvents the flat tyre, and definitions drift from each other causing double work and organisational chaos.
The "gold layer" in your warehouse? It's usually a mix of model and workaround: pre-built, denormalised tables shaped for specific tools because those tools can't traverse normalized data on their own. Star schemas and OBTs are often chopped-up 3NFs or snowflakes built for tool limitations.
2. The need for a separate semantic layer
Around 2020-2022, companies started extracting semantic layers from BI tools into standalone products. Cube, dbt Semantic Layer, and others emerged.
The reason: if we define metrics and relationships once, outside any tool, every consumer (dashboards, APIs, notebooks, LLMs) can share the same definitions.
But the execution was painful. These products require:
- YAML configuration files (hundreds or thousands of lines)
- Manual annotation of every column
- A server or cloud service to run
- Upfront understanding of every relationship before you start
Everyone hates semantic mapping. It's tedious, declarative, and requires a lot of people-work with little hands-on coding.
3. What's special about BSL (Boring Semantic Layer)
The Boring Semantic Layer, championed by Julien Hurault, represents a philosophical counter-movement to the Modern Data Stack's tendency toward complexity. The name "Boring" is a deliberate rejection of "resume-driven development" where engineers build overly complex stacks that serve their careers rather than the business.
The philosophy: Pragmatism over hype
Julien argues that "fancy semantic reasoning" and elaborate knowledge graphs often fail in production. Performance tanks when you add dynamic join path optimization. Industry-scale implementations struggle with latency from complex ontologies.
BSL embraces the opposite: deterministic, explicit definitions. It doesn't try to "guess" join paths or infer relationships through magic. You define the logic explicitly. When an LLM or dashboard requests a metric, the resulting SQL is predictable, optimized, and debuggable.
This is the "boring" trade-off: you sacrifice cleverness for governed simplicity and reliability.
Technical differentiators
A library, not a platform. pip install boring-semantic-layer. No servers, no infrastructure, no SaaS subscription. Cube runs as a cluster of services with its own caching layer. dbt Semantic Layer requires dbt Cloud. BSL runs inside your Python process, in a script, a Lambda function, or a laptop. This makes it developer native, integrating seamlessly with all other developer tools, as opposed to high impedance, “walled garden”, commoditised products.
Built on Ibis for portability. Ibis is the "Rosetta Stone" of SQL. A metric defined as sales.sum() compiles to DuckDB SQL locally, Snowflake SQL in production, BigQuery SQL in another team. Same semantic model, any backend. No "works on my machine" problems.
Python-native, not YAML-native. While BSL uses YAML for configuration, the runtime is Python. Dimensions and measures are Python callables with full IDE support—autocomplete, type checking, debugging. Data scientists can import the semantic model directly into notebooks or Streamlit apps without HTTP calls to external servers.
The "One-Man Data Team" enabler. BSL democratizes enterprise-grade governance. A single engineer can orchestrate ingestion (dlt), transformation, semantic definitions (BSL), and visualization (Streamlit), all running in scheduled scripts or simple containers. No Kubernetes, no Airflow clusters.
The agentic vision: MCP Integration
BSL's most forward-looking feature is native support for the Model Context Protocol (MCP). This transforms the semantic layer into the API for AI.
Without a semantic layer, LLMs resort to "schema stuffing", raw table definitions crammed into prompts. They guess column names, hallucinate join paths, and write syntactically correct but semantically wrong SQL.
With BSL + MCP, the LLM doesn't write SQL. It queries the semantic layer's interface: list_metrics(), get_dimension_values(). It's constrained to the "menu" of validated metrics. This shifts the LLM from "SQL writer" to "Semantic Query Writer", dramatically reducing hallucinations.
This enables "Chat-BI": natural language becomes the interface for data, backed by deterministic, reliable semantic definitions.
4. What this demo does: dlt + LLM + BSL
This demo explores a fusion: dlt's automatic schema discovery + LLM inference + BSL.
We use the Sakila database: MySQL's classic movie-rental sample dataset with rentals, customers, films, inventory, staff, and snowflake schema of addresses → cities → countries. This database is a classic example of a normalised, or 3nf (Third normal form) database, as opposed to classic denormalised “star” or “one big table” schemas.
What dlt automates
The key insight: dlt already knows your schema. When you extract from a database, dlt captures:
- Foreign keys automatically via
resolve_foreign_keys=True. dlt reads the database's referential integrity and records every relationship. No manual join definitions. - Primary keys, column types, nullability, all captured from the source database metadata.
- Custom annotations via
apply_hints(). You can tag columns as PII, as dimensions, as filterable, metadata that travels with the schema.
This schema becomes the input to the LLM. The pipeline encodes the dlt schema and sends it to GPT, which returns a structured semantic model: fact tables, measures with aggregations, dimensions with bucketing expressions, relationships.
One command, python pipeline.py -i runs extraction AND semantic inference. The output is a semantic_model.json that BSL consumes directly as you can see in the image below.
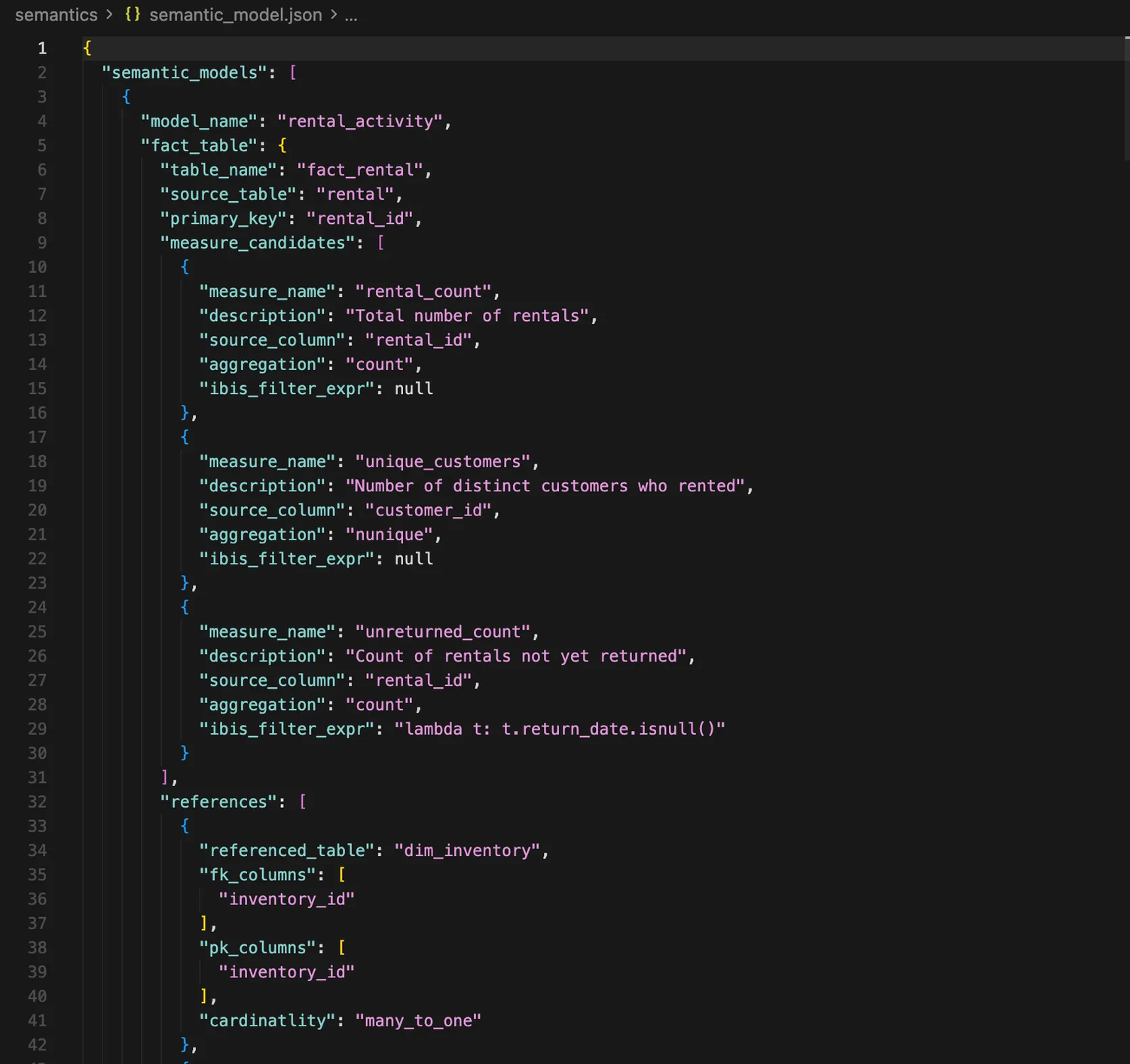
The automation chain
- dlt reads MySQL → captures schema + foreign keys + your annotations
- Schema encoded and sent to LLM → returns structured Pydantic model with dimensions, measures, relationships
- BSL loads the JSON → builds semantic model with joins already defined
- Five interfaces consume the same model → no duplication
The LLM doesn't see raw SQL. It sees a structured representation of your schema with all the relationships dlt discovered. It proposes:
- Which table is the fact (rental)
- What measures make sense (rental_count, unique_customers, unreturned_count with filter)
- Which columns are dimensions, with optional bucketing (release_year → release_decade)
- Ibis lambda expressions for derived columns
Five consumers, one source of truth
To access the data, we can do it in multiple ways, here is the breakdown of the interfaces and their functions:
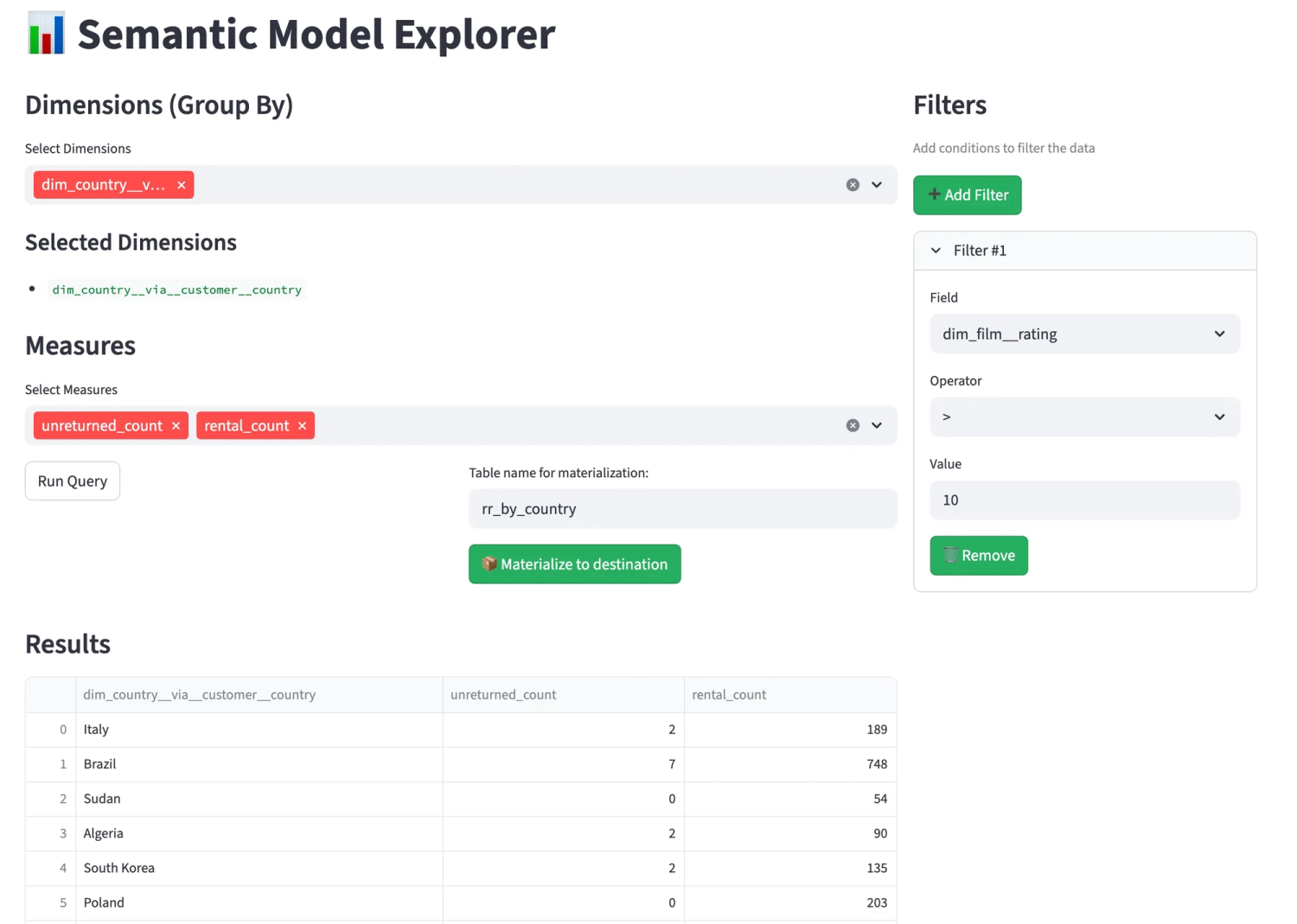
- Streamlit Explorer: A point-and-click interface that lets you select dimensions, measures, and filters to run queries. It can also materialize results back to the warehouse.
- FastAPI Server: Provides REST endpoints (like
GET /dimensions,GET /measures,POST /query) and returns data in JSON or Parquet formats. - ER Diagram Generator: Automatically generates a visual relationship diagram based on your semantic model's metadata.
- MCP Chatbot Server: Exposes the semantic model via the Model Context Protocol (MCP), allowing LLMs to use it as a tool.
- Materializer: Writes the results of any semantic query back to your data warehouse as a new table using dlt.
Pictured: Querying becomes a matter of selecting your metrics and dimensions
5. Implications
Governance as Code
Because semantic definitions are text files (YAML/Python), they're subject to standard software engineering governance. Changes go through pull requests, get diffed against previous versions, and run through CI/CD before production. This moves governance from a bureaucratic process (meetings and spreadsheets) to an engineering process (git and tests).
If the definition of "Active User" changes, it's updated in one place. Because BSL sits upstream of consumption, the change propagates instantly to dashboards, APIs, and AI agents.
The gold layer becomes "Boring" too
The demo uses a normalized database in 3nf, which is a layer short of what we typically see in a "gold" or serving layer. A semantic layer does not replace modelling - it requires at the very least 3nf tables that represent consistent, well defined business entities.
However not all modelling is made equal. Most modern analytical models denormalise 3nf models to a snowflake, star or OBT schema for technical limitations: tooling and compute complexity of joining on the fly. If your data already contains the entities and facts you want to report on, the only reason to denormalise is to support faster calculations.
So while in theory we can avoid some modelling, we will still need a clean modelled conformed layer, in 3nf or more denormalised.
Analytics engineers don't need to do it manually
The LLM drafts 80% of the model. You review for hallucinated joins, incorrect aggregations, missing business context. Minutes instead of days. You're curating and validating, not writing declarative yaml from scratch.
Multi-modal consumption becomes real
The same definitions serve dashboards, APIs, and LLM agents. MCP means the chatbot doesn't write SQL but it queries the semantic layer instead. This is "Chat-BI": natural language querying backed by deterministic definitions.
Conclusion
The boring semantic layer solves a real problem: enabling multi-modal data consumption, classic BI, APIs, and AI agents, from a single source of truth, with minimal modelling
With this experiment, we've shown how we can use dlt metadata to quickly bootstrap a semantic layer on top of a normal database and make it ready for multimodal usage. The LLM drafts 80% of the model in seconds. You review, tweak, and approve. Your future self (and your business users) will thank you.
The best data architecture is boring. It just works.
Resources:
Our demo: https://github.com/dlt-hub/boring-semantic-layer-demo
Julien's BSL on Github: https://github.com/boringdata/boring-semantic-layer
Julien's substack: https://juhache.substack.com/p/boring-semantic-layer-v2
We're building dltHub!
We're inspired by the boring semantic layer in our commercial product dltHub. dltHub is a LLM-native data engineering platform that enables any Python developer to go from raw data to real insights in hours, even without a large data team.