Text-to-SQL is a definition problem: build the canonical model first
Text-to-SQL doesn’t break because models can’t write SQL — it breaks because they don’t know what your data means. Write the meaning down first as a canonical knowledge layer, and use that one spec to both build the model and answer questions over it.
 Adrian Brudaru,
Adrian Brudaru,
Co-Founder & CDO
On this page
- 1. A canonical model is already the structure the agent needs
- 2. What you are missing is a canonical knowledge layer, not a data model
- Does the meaning help?
- How large a canonical model can it handle?
- 3. Each knowledge part has a different job
- 4. This is already how GraphRAG works
- 5. Build the canonical knowledge layer once, use it twice
- 6. Shifting the canonical model left collapses the time to an answer
- 7. The honest limits everyone is reaching
- 8. Write the definitions first
Text-to-SQL is not a problem of writing SQL. The agent can write SQL fine. The problem is that it does not know your data. It does not know what your tables mean, how they connect, or which one holds the answer. So it guesses, and it keeps going.
Getting to a canonical model is already a lot of work. You ingest raw data, transform it, resolve entities, align grains, and near the end you settle the governed definitions — the clean tables everyone is meant to agree on. That cost is normal, and it is high. Then, to make text-to-SQL work on top of it, the usual advice is to add one more layer: a semantic or knowledge layer that restates what the tables mean for the agent. That is more work on top of work that was already heavy. And the definitions in that new layer never guided the modeling, so the two can drift apart.
This is roughly what the best setups do today. Anthropic, in their own analytics stack, write the meaning into skills that the agent reads on top of a governed warehouse. The academic version is older and has a name: ontology-based data access (OBDA). The idea is to answer questions against a layer that describes what the data means, instead of against the raw tables. It has been around since well before LLMs. Both approaches put a meaning layer over a model that already exists. Both work. And both leave you maintaining the meaning twice — once in the modeling, once in the layer on top.
We think the order is backwards, and at dltHub we are building from the other end. The definitions are the expensive, valuable part, so write them first. The spec lives at the source, in a form both a person and an agent can read. You then iterate that spec against the raw data to produce the canonical model, with a human resolving the calls that need judgment.
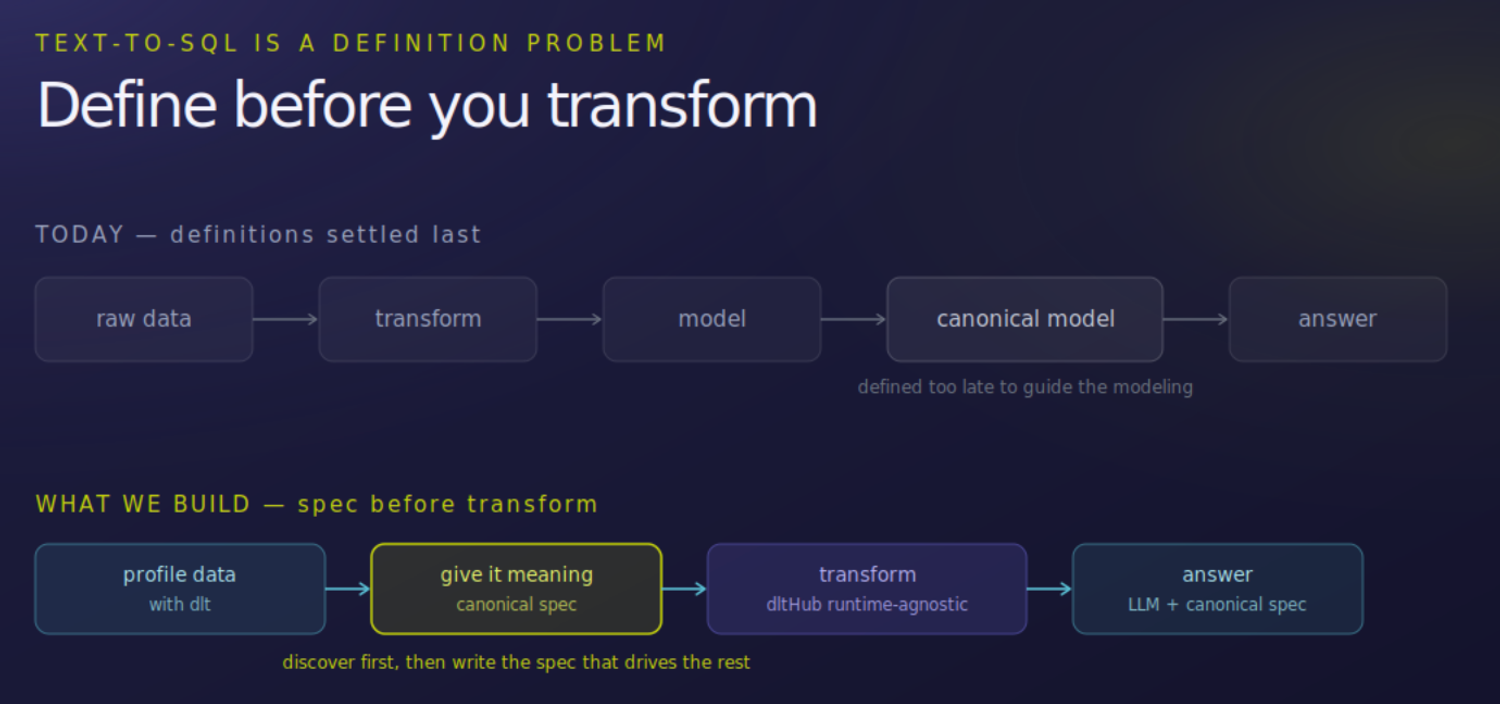
The same spec that built the model is what the agent reads to answer questions over it. You keep the two in sync by editing one thing. The definitions are no longer something you rebuild at the end and bolt on for the agent. They are where you start.
1. A canonical model is already the structure the agent needs
The agent is missing the definitions, not the skill. Give it a clear question and a known schema and it writes correct SQL — it plans, joins, and fixes its own syntax. But it has never seen your business, so it picks something plausible and runs with it, and a wrong choice produces a clean number that looks as real as a right one.
Those definitions are something you can write down. A canonical model — your governed entities, their relationships, their join keys — is most of that written down already. It also happens to be the same object as a knowledge graph, just in a different notation.
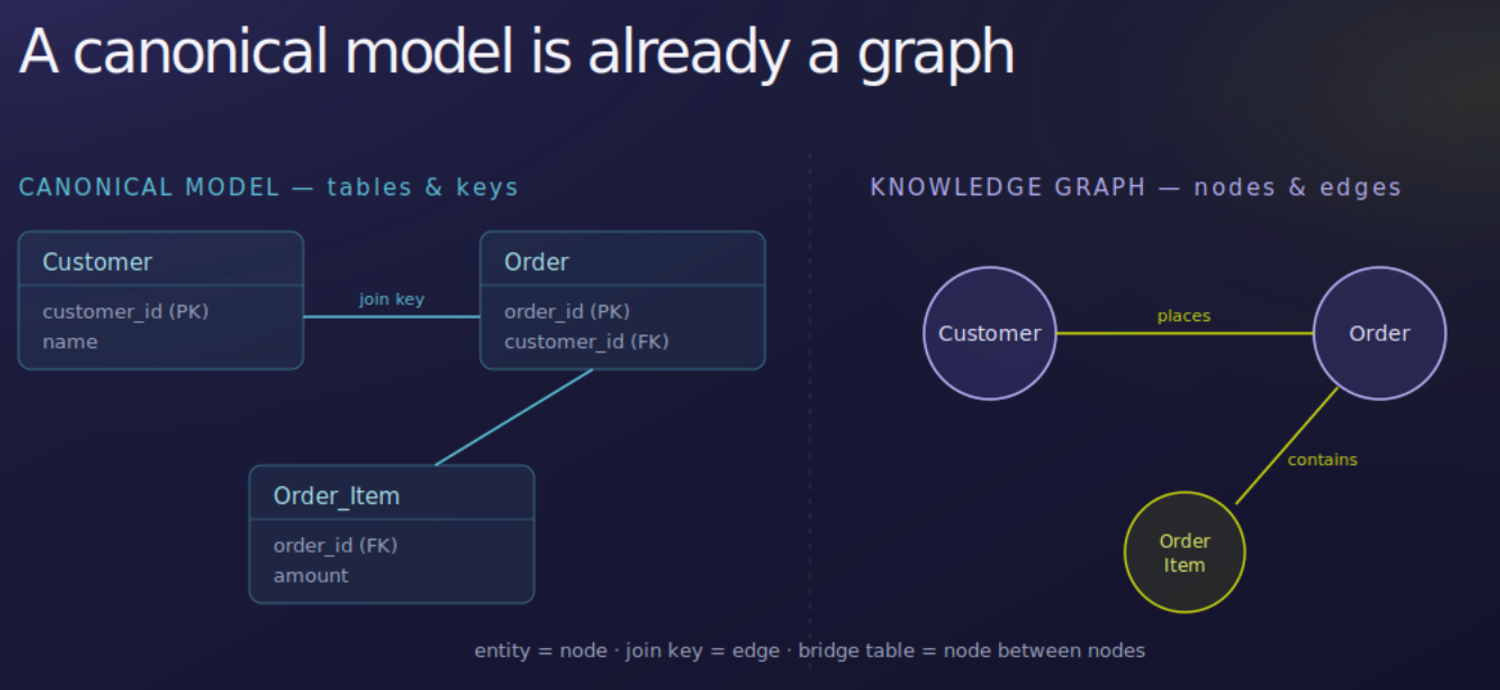
This is not a coincidence. A knowledge graph and a canonical model both describe the same thing — the entities in a domain and how they connect — which is why OBDA works at all: a system answers against that meaning layer instead of against the raw tables. The agent reasons over a clean description of what exists and how it relates, decides what the question maps to, and only then touches the data.
That used to be hard. The meaning had to be written as a formal graph in a language like OWL, and queried with formal tools. That is why it stayed mostly in research and large enterprises. What changed is the reader. The reader is now a language model, and it does not need a formal graph — it reads plain text and follows relationships described in words. Give it a description of your entities, what connects to what, and which table holds which fact, and it can walk that structure the way a graph query would: start at the concept in the question, follow the links to the right tables, and stop.
This is why structure helps the part that breaks. The main failure in a large warehouse is retrieval: finding which of a thousand columns the question is even about. A graph turns that search into a short, guided walk instead of a guess across the whole schema.
So you do not need to build a knowledge graph. You already have one. A canonical model written down, described in plain language, is a naive knowledge graph: not the full formal apparatus, but the same shape, and enough for the agent to use natively.
This also shows what the canonical model is missing. OBDA reaches the data through a layer that carries both the structure and its meaning. The canonical model is only the structural half — it shows that orders connects to customers. It does not say what "revenue" counts, which users are in scope, or which metrics the business defines. To get the OBDA behavior, you supply that meaning alongside the structure.
2. What you are missing is a canonical knowledge layer, not a data model
A canonical model tells you the shape of the data. It does not tell you what the shape means. Meaning is lost on the way from a plain-language description of the business to a set of entities and relationships — the structure survives, the meaning does not.
So you have to write the meaning down too. The document that holds both — the structure and the meaning — we can call a canonical knowledge layer (or a canonical spec). It is not a data model. It is the data model plus the two things a data model leaves out:
- Taxonomy: what is in scope, what is out, and why. Which metrics exist. Which ones do not.
- Ontology: what the relationships actually mean. What a join computes. Which population a count is over.
Put plainly, the canonical knowledge layer is a manual for how the canonical model ties back to the business and the questions people ask of it. A data model says orders joins to customers on customer_id. The knowledge layer says that revenue means billed revenue, that a "user" for this metric means a billed customer and not a signup, and that the question "what is our churn" is out of scope because churn is not defined here yet.
This is what the Anthropic data team does. They write the meaning into skills holding the table descriptions, the scope, the join rules, and the traps a senior analyst would warn you about. By their account it is the difference between an agent that is unusable on raw tables and one that is reliable. The model and the data stayed the same; the meaning made the difference.
How far does writing the meaning down actually get you? The honest answer separates two things benchmarks usually mash together: whether the meaning helps, and how large a canonical model you can point it at. They have different answers and different evidence.
Does the meaning help?
On this the evidence is consistent and not subtle. The closest applied case is Anthropic's own analytics stack: their agent did not exceed 21% accuracy on raw tables, and rose to consistently above 95% in aggregate once the meaning was written into skills (claude.com). That is a team running this in production against a real warehouse, not a benchmark. Controlled tests point the same way. A 2026 paired study from Cube (arXiv:2604.25149) ran 100 questions against Claude Opus 4.7, Sonnet 4.6, and GPT-5.4, each twice: once with only the schema, once with a short markdown document of measures and rules. The document added 17 to 23 points for every model. With it, the three models scored within a point of each other (67.7–68.7%); without it, they clustered lower (45.5–50.5%). In other words, once the meaning is there, the model you pick barely matters — a small model with the meaning beat a frontier model without it.
"The presence of the semantic-layer document accounts for essentially all of the significant variance; model choice within tier does not."
— Rumiantsau & Fokeev, Cube, 2026 (arXiv:2604.25149)
The effect is not new, and it has held as the models changed. Back in the GPT-4 era, the BIRD benchmark (arXiv:2305.03111) showed the same shape: removing the one-sentence "evidence" attached to each question dropped GPT-4 from 54.89% to 34.88% — a 20-point fall from taking away nothing but the written-down meaning. Three years, three model generations, one result: the model was never the variable, the meaning was.
These tests load the whole schema and the whole document at once, on a dataset small enough to fit. That proves the meaning helps, but only when everything fits in context. What happens past that size — when the canonical model is too large to load whole — is the next section.
How large a canonical model can it handle?
Here the honest answer is no — a model cannot handle a huge schema, which is the whole reason canonical models exist. A raw schema with thousands of columns sinks frontier models to the low twenties (Spider 2.0); the agent is reduced to guessing which columns a question means. A canonical model removes that guesswork by replacing the raw schema with a few dozen distinct, governed entities. So the real question is not whether a model can swallow a huge schema, but how you hand it the few entities a question needs and nothing else.
That part is already solved. Feeding the agent the relevant slice of a graph — not the whole thing — is what question-answering over knowledge graphs has done for years: find the entities the question refers to, expand a few hops to their neighbours, and answer over that small subgraph. GraphRAG does the same over graphs built from documents. It transfers directly here, with one advantage: you do not have to extract a graph first, because a canonical model already is one. And it is a clean graph, where the connections are local. You answer "revenue per customer" by walking from revenue to customer, not by chaining through seven bridge tables. The neighbourhood is small, so the slice you feed the model is small.
The order matters: you write the meaning down first, and add retrieval only once the model is large enough that finding the right slice is the work. Reaching for the second before doing the first is the common mistake.
3. Each knowledge part has a different job
There are three parts — canonical model, taxonomy, ontology — and each one stops a different kind of wrong answer. The clearest way to see it is to take one question and add the parts one at a time.
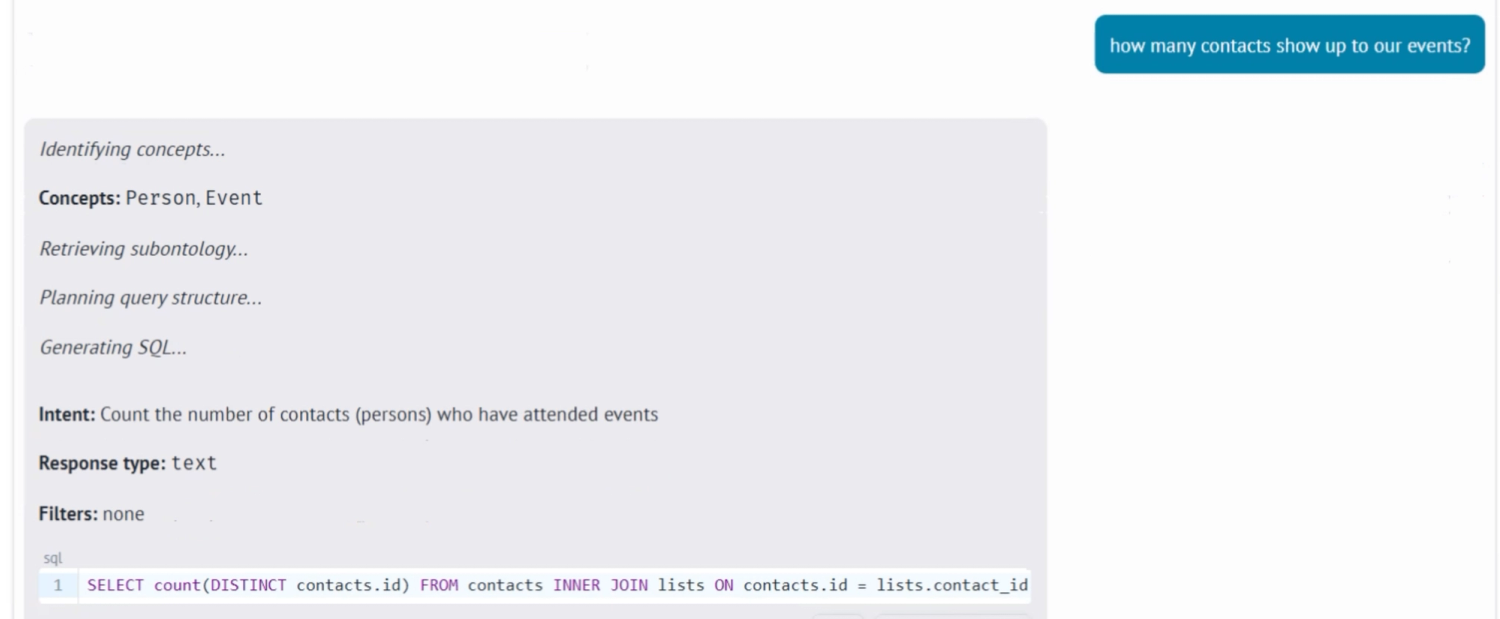
The question: what is our ARPU (average revenue per user)?
- With only the canonical model: the agent finds the right tables and writes working SQL. But if you ask for a number that is not defined anywhere, it makes one up. On trick questions, that is about a 5% fabrication rate. The structure tells it where to look, not what is real. In the literature, giving the model the right tables, joins, and filters is what moves accuracy most: Snowflake's Cortex Analyst measured about +20% over the bare LLM from exactly this (snowflake.com).
- Add the taxonomy: now the agent knows what exists and what does not. Asked for a metric that is out of scope, it says so and gives a reason, instead of inventing an answer. This is the part that lets the agent say no. Abstaining is its own measured skill. TrustSQL (arXiv:2403.15879) tests text-to-SQL on refusing questions it cannot answer, and a scope-aware setup reaches about 0.8 accuracy at spotting out-of-scope questions (arXiv:2512.21345).
- Add the ontology: now the meaning is fixed. ARPU stops being "all revenue divided by all active users," which quietly mixes billed customers with people who have not paid yet. It becomes "revenue from billed customers, matched to billed customers, in the same company and month." The SQL was always valid; now it computes the right thing. This is the error that survives everything else: SQL that runs but counts the wrong thing. Checking the query against the ontology's stated relationships catches it. data.world's ontology query check beat the plain knowledge-graph baseline on exactly these mistakes (arXiv:2405.11706), and SQLens reports up to +20% accuracy from finding and fixing them (arXiv:2506.04494).
The agent, the data, and the question never changed — only the document did. Each part removed one class of error: the canonical model put it on the right table, the taxonomy let it refuse what does not exist, the ontology fixed what the query actually computes.
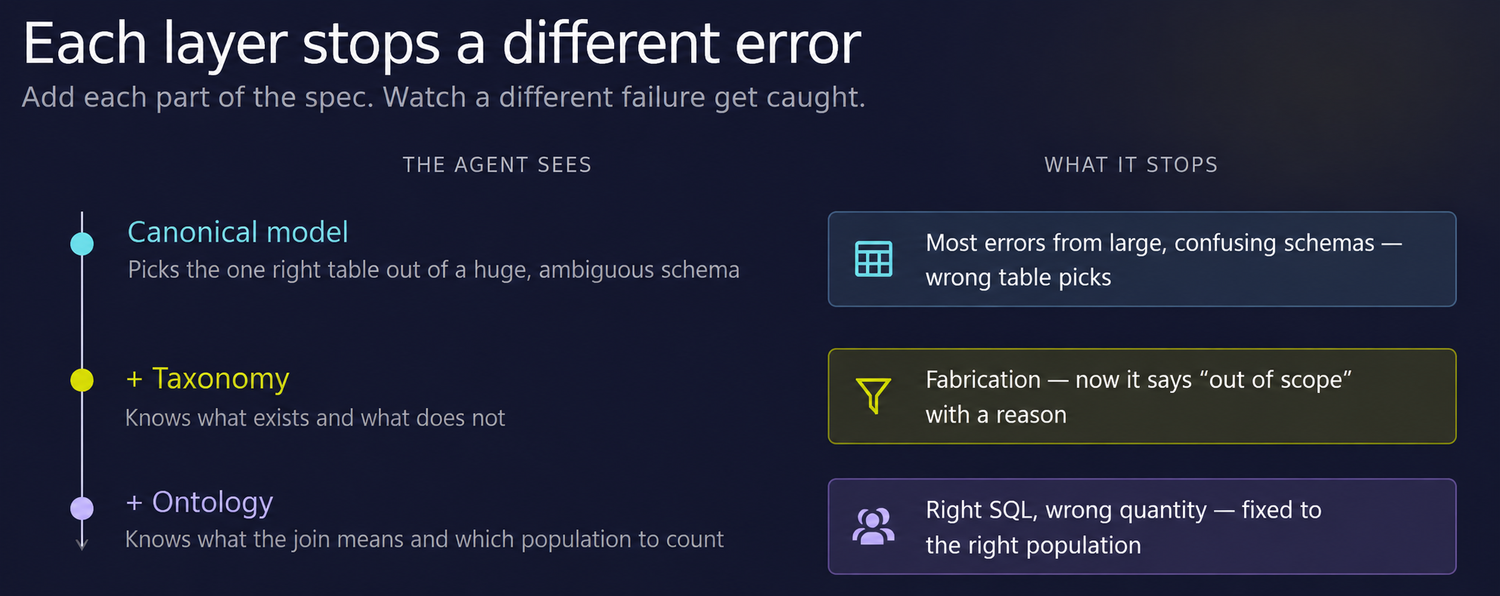
None of this makes the agent infallible. Even with the meaning written down, it can still misread a question the document covers. That is why the ability to say "I cannot answer this from what is defined" matters as much as any correct answer — a model that abstains when unsure beats one that is confidently wrong.
4. This is already how GraphRAG works
Mature unstructured-data stacks already work this way: an ontology defines the concepts, a knowledge graph is built to match that definition, and queries run over the graph rather than over raw text. The definition comes first and everything downstream is derived from it — the same order this post argues for over tables, where the canonical knowledge layer is written first, the data is modelled to fit it, and questions are answered through that same layer.
Naive RAG is the first version: cut text into chunks, embed them, retrieve by similarity, generate an answer. It fails in real use because similarity has no model of the data — it matches words, not meaning. Ask "how many millimeters is the part?" and the retriever pulls back chunks about length and chunks about diameter, because both are measured in millimeters and both look similar to the question. It cannot tell which dimension you meant, because it does not know what either one is — it only knows they read alike. Two values close in wording but different in meaning are exactly what similarity cannot separate.

So the field moved to GraphRAG: stop retrieving flat text, build a graph first, then answer by walking the graph. An LLM pulls entities and relationships out of the documents, stores them as nodes and edges, and retrieval becomes a walk over structure instead of a fuzzy match over strings.
GraphRAG pulls a graph out of text because prose has no built-in structure at all. Raw tables look like the opposite case — they already have structure — but only half of what you need. The column names carry none of the meaning: rev_d, cust_t, and a foreign key tell you nothing about what revenue counts or which customers are billed.
Our stack is the same pipeline, run over dense data instead of sparse. The text world starts from unstructured prose, so it has to extract a graph before it has anything to query. We start from data that is already structured. We build the tables, and a clean canonical model is already a graph — so we get the virtual knowledge graph for free, without extracting anything.
What the data does not give us is the meaning, and that is the one piece the text world also has to supply. Raw tables do not carry it. It comes from the business people and the data's creators, and writing it down is what the ontology in our stack is. Ontology, knowledge graph, query: the same three parts as a document stack, ours sitting over rows. If you have already built ETL into a canonical model, the structure is done — what is left is to write the meaning down.
5. Build the canonical knowledge layer once, use it twice
Everything so far has been about using the layer at query time. That already pays for writing it. But once you have a spec precise enough for an agent to read, code generation off that spec is possible — so why stop at querying? Use the same spec to build the model.
At dltHub we built data-engineering agents that generate ingestion and modeling from the spec. So the same spec that answers questions also builds the actual data model — which makes keeping the knowledge layer and the data layer in sync a natural consequence rather than a separate chore. You edit one document; both move together.
In practice the workflow looks like this:
- Start with a dlt pipeline to profile your data. You need to see what is actually in the sources — the columns, the shapes, the values — before you can describe them.
- Model it with the agent. In the Workbench, this kicks off a process that bootstraps your ontology and uses it to generate the canonical model.
- A human curates and iterates, because the hard parts of modeling do not resolve themselves. Entity resolution is the obvious one — deciding that two records are the same customer, or that two columns are the same metric under different names, takes judgment the spec has to encode. The machine does the volume; the human resolves the ambiguity.
- Keep that same spec beside the warehouse as a virtual knowledge graph — no copy into a separate graph database, since the structure is already in your tables.
At query time the agent reads it before it touches the data, in order:
- Taxonomy — is this question in scope? Does this metric exist? Does this entity exist? If not, stop and say so.
- Canonical model — which entities and tables does this map to? How do they join? Which part of the graph do you feed to the context?
- Ontology — what does this relationship mean? Which population, which grain, which window?
- Then write SQL against the real tables.
This is why the answers are accurate and stay that way. The layer that built the model is the same layer the agent reads to query it, so the meaning the agent applies cannot drift from the meaning the model was built on — they are one document, not two that fall out of step. And because that document is the source, editing it is how you change the system: update a definition and you both regenerate the affected part of the model and update what the agent reads, in one move.
In our small-scale experiments with a customer, reusing the spec, we observed similar performance on small canonical models to what the Anthropic team reports.
6. Shifting the canonical model left collapses the time to an answer
In our experiments, once a canonical model is in place, asking a new question that needs new taxonomy is enough to move the whole pipeline: the agent proposes the ingestion and canonical-model changes required to answer it. The question drives the model forward, instead of waiting on a separate modeling project.
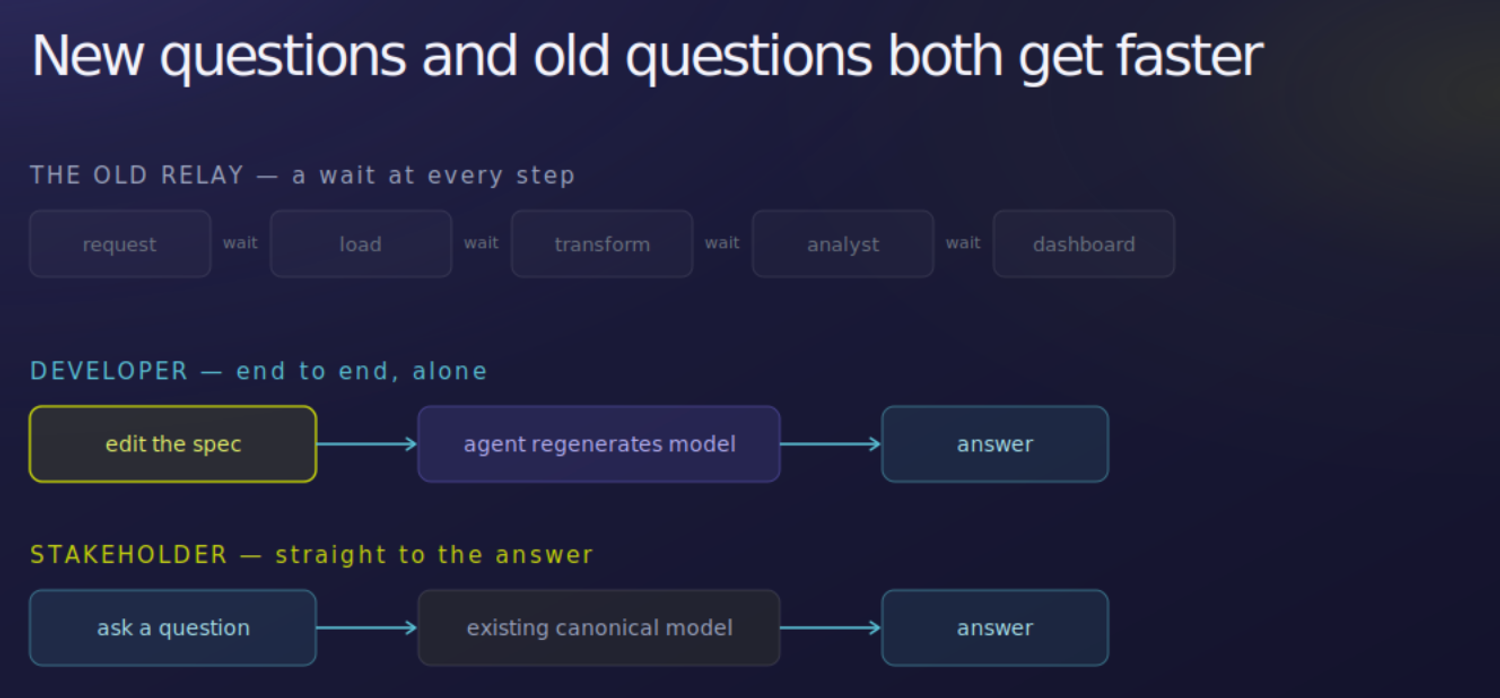
That matters because the path from question to answer is normally a chain of handoffs — request, load, transform, analyst, dashboard — and each handoff is a wait. The popular plan is to drop an agent at each step to speed the handoffs, but a faster relay is still a relay, and an agent that builds a dashboard faster is still building a dashboard when what the person wanted was the answer.
Shifting the canonical model left removes the chain, and it helps two roles differently. A developer can go end to end alone — curating the spec and letting the agent regenerate the model and ingestion, with no team of specialists to execute each step. A business stakeholder does not wait on that at all: for anything the model already covers, they get the answer straight from it. New questions move at the speed of one person curating a spec; existing ones at the speed of a query.
The modeling is the part we are building first: a tool that takes the spec and your raw sources and produces the canonical model, with a human confirming the calls that need judgment. In our early deployments that runs 20 to 50 times faster than modeling by hand. Approaches that keep a person in every decision cap around 5 to 10 times, because the last mile stays manual.
7. The honest limits everyone is reaching
The point of all this is self-service: a stakeholder asks a question and gets an answer without an analyst in the loop. That only works if the answer can be checked, so the canonical knowledge layer ships every answer with its SQL, its definitions, and its lineage. You verify it instead of trusting it blind — and a wrong answer becomes one you can catch, not one you take on faith.
The trade-off is that the agent is only as good as the document. If a real metric is not in the layer, the agent refuses a question it could have answered. So you are setting a dial between coverage and safety, and writing more of the layer is how you move it. That is the safe failure. The dangerous one is the quiet wrong answer: a query that joins orders to products, skips the subscription logic, and returns order value labelled as recurring revenue. It runs without error. The number looks normal. It measures something else. The first time that reaches a stakeholder, trust in the whole system is gone, however accurate it is on average.
No one has fully solved this, and the most honest account comes from the people running it at scale. Anthropic automates most of their internal analytics this way, at roughly 95% accuracy in aggregate (claude.com) — which means they accept that some answers are wrong and design around it. They say plainly that the silent, plausible, wrong answer is the failure they have not robustly solved. Their defenses are the ones worth copying. Route board-level numbers to fixed, governed SQL instead of letting the agent write them fresh. Attach provenance to every answer — source, freshness, owner — so a reader can judge how far to trust it. Make the agent abstain rather than guess. And check each domain's top metrics against a trusted dashboard.
The direction this points is to move the human check from every answer to the spec. Verify the layer once — the definitions, the join paths — and every answer drawn from it inherits that scrutiny, with provenance so a skeptic can still drill into any single number. You are not asked to trust an agent; you are handed a checkable answer.
8. Write the definitions first
Text-to-SQL is not a flaky feature that sometimes breaks. It is spec-driven development that breaks when you skip the spec.
So the conclusion is simple: write the canonical model as a spec, first, and generate the data and the answers from it. What you get for doing it:
- One artifact instead of two. The definitions that build the model are the definitions the agent answers with, so the knowledge layer and the data layer cannot drift apart — you maintain one document, not two that fall out of sync.
- Modeling stops being a separate project. A new question that needs new taxonomy drives the model forward: the agent proposes the ingestion and model changes to answer it, instead of a ticket waiting on a modeling team.
- Faster, with fewer people. Generating the model from the spec runs 20 to 50 times faster than building it by hand, and a single developer can take it end to end.
- Self-service that is actually checkable. Stakeholders get answers straight from the model, each shipped with its SQL, definitions, and lineage — so an answer is something you verify, not something you trust blind.
- It scales. A clean canonical model is already a graph, so a large one is handled by retrieving the slice a question needs — a solved problem, not a wall.
This comes out of the ontology-driven data modeling work in the dltHub AI Workbench. If you want to look at what exists or follow where it goes:
- The AI Workbench, including the modeling tooling → https://github.com/dlt-hub/dlthub-ai-workbench
- The Agentic Data Engineering course, if you want to work through this hands-on → https://dlthub.learnworlds.com/courses
- The ontology toolkit preview → https://dlthub.com/blog/ontology-toolkit-preview