Agents can write dlt pipelines. Now they can run & deploy them.
Today we are introducing the dltHub AI Workbench: an infrastructure layer for dltHub that makes AI-generated dlt pipelines trustworthy enough to run and deploy in production.
 Matthaus Krzykowski,
Matthaus Krzykowski,
Co-Founder & CEO
On this page
- I. Writing code was never the hard part
- II. We are building the missing infrastructure
- 1. REST API pipeline toolkit
- 2. Data exploration toolkit
- 3. Data transformation toolkit
- 4. dltHub deployment toolkit
- III. dltHub: where it all clicks
- IV. How it works in practice
- Generating the pipeline
- Validating the data
- Using the data
- Deploying to production
- Propose, verify, enforce: How Agents, humans and tools do best together
- Trust in the agent's work is built into dltHub, not bolted on
- Start here
Today we are launching the Public Preview of dltHub with the initial release of the dltHub AI Workbench: an infrastructure layer for dltHub that makes AI-generated dlt pipelines trustworthy enough to run and deploy in production.
I. Writing code was never the hard part
Agents are authoring entire data systems. Not just scripts, but full dlt pipelines with authentication, pagination, schema handling, incremental loading. The shift happened faster than anyone expected, and it's not slowing down. At dlt alone, we recently saw 81,000+ custom sources created in a month based on 550,000+ LLM docs requests. Monthly dlt downloads accelerate, crossing 9M+ downloads on PyPI. Agents are the primary builders now.
But writing code was never the hard part of data engineering. The hard part is everything before and after: Does the data match what you expected? Is it being loaded and used correctly? Did the schema drift? Is this pipeline safe to run against production? Can someone other than the agent understand how it works?
That's the frontier we're building toward. Not just AI that generates pipelines, but a platform where AI-generated pipelines are trustworthy, observable, and production-ready from the first run. A platform where agents and tooling for humans work together - each doing what they're best at.
II. We are building the missing infrastructure
Today we're taking another big step. We're releasing the AI Workbench for dltHub.
The dltHub AI Workbench is a set of toolkits that ship with dltHub. Each one gives your coding assistant a complete, structured workflow for a specific phase of data engineering - not autocomplete, not a chatbot on a dashboard. A guided sequence of skills, commands, rules, and an MCP server that the agent follows step by step, with guardrails it can't skip.
One prompt. One toolkit. One workflow.
(3 minute second short, there's also a full length 25min below)
The initial dltHub AI Workbench toolkits launch today.
1. REST API pipeline toolkit
Tell your agent what data you want from any REST API. The toolkit handles the rest: endpoint discovery, authentication, pagination, schema normalization, incremental loading, secrets management. A complete dlt pipeline from a single conversation.
There are already 9,700+ pre-built REST API configurations at dlthub.com/context. The agent looks up your API there first - if a configuration exists, it uses it. If not, it reads the API docs and scaffolds one from scratch. Either way you get a production-grade pipeline, not a throwaway script. Schema inference, data contracts, and incremental loading are available from the first run. And when the agent finds multiple valid approaches, it surfaces the choice to you instead of picking one at random.
2. Data exploration toolkit
Once data is loaded, explore it without leaving your session. The dltHub dashboard gives you pipeline run history, a table schema browser, and a live SQL query interface. Ask the agent to validate your data and it produces a full validation table - row counts, primary key checks, timestamp verification, nested object inspection - pulling table previews via the MCP server automatically.
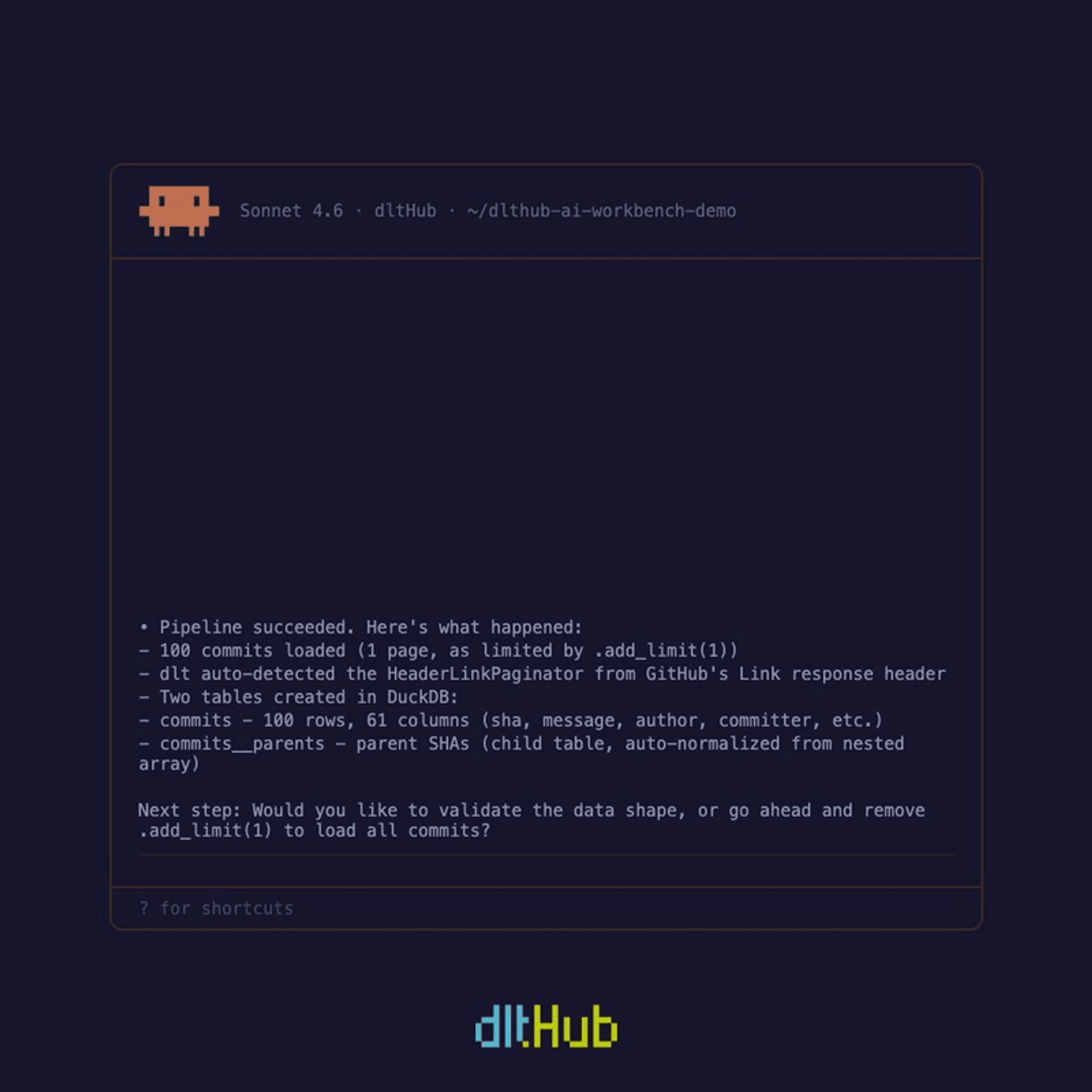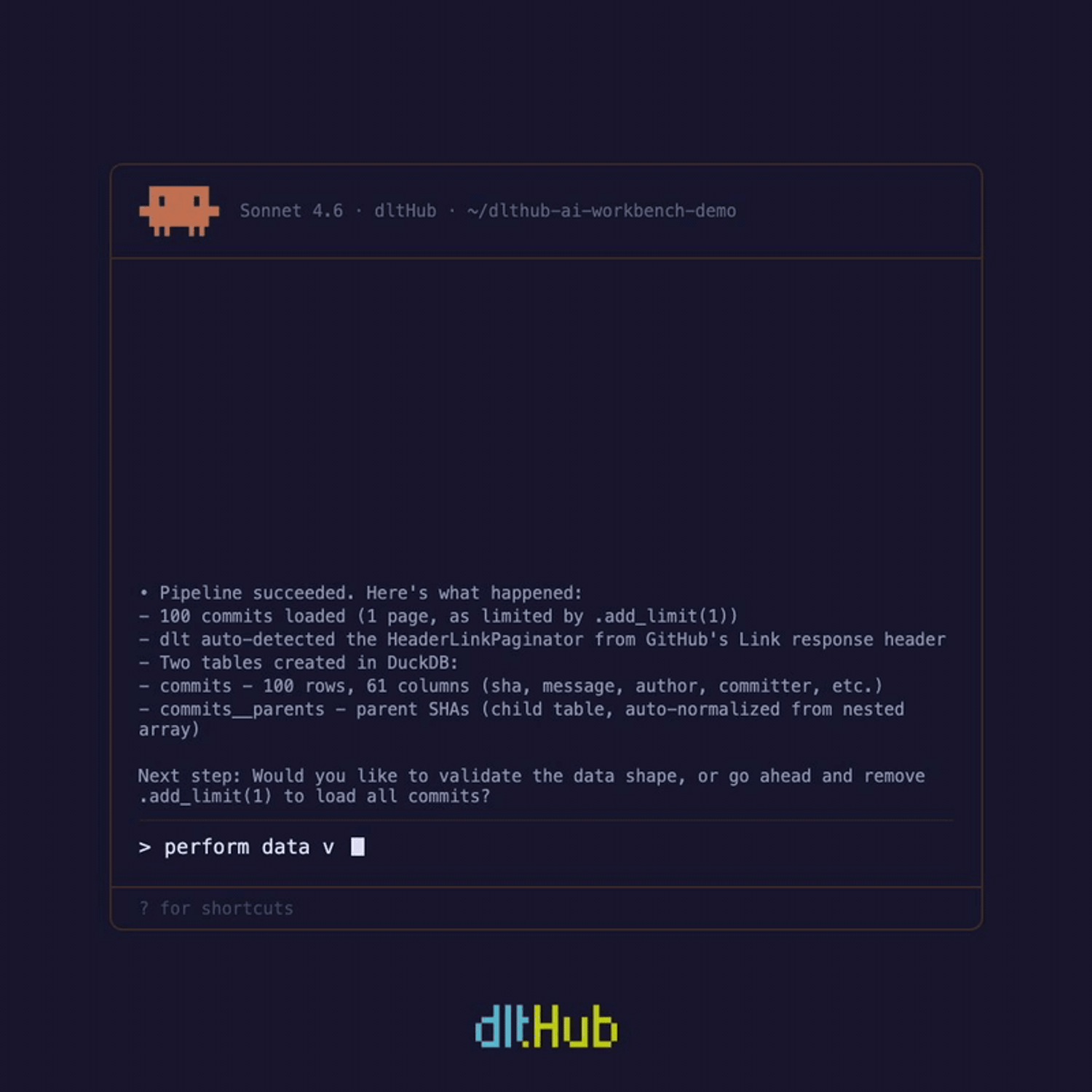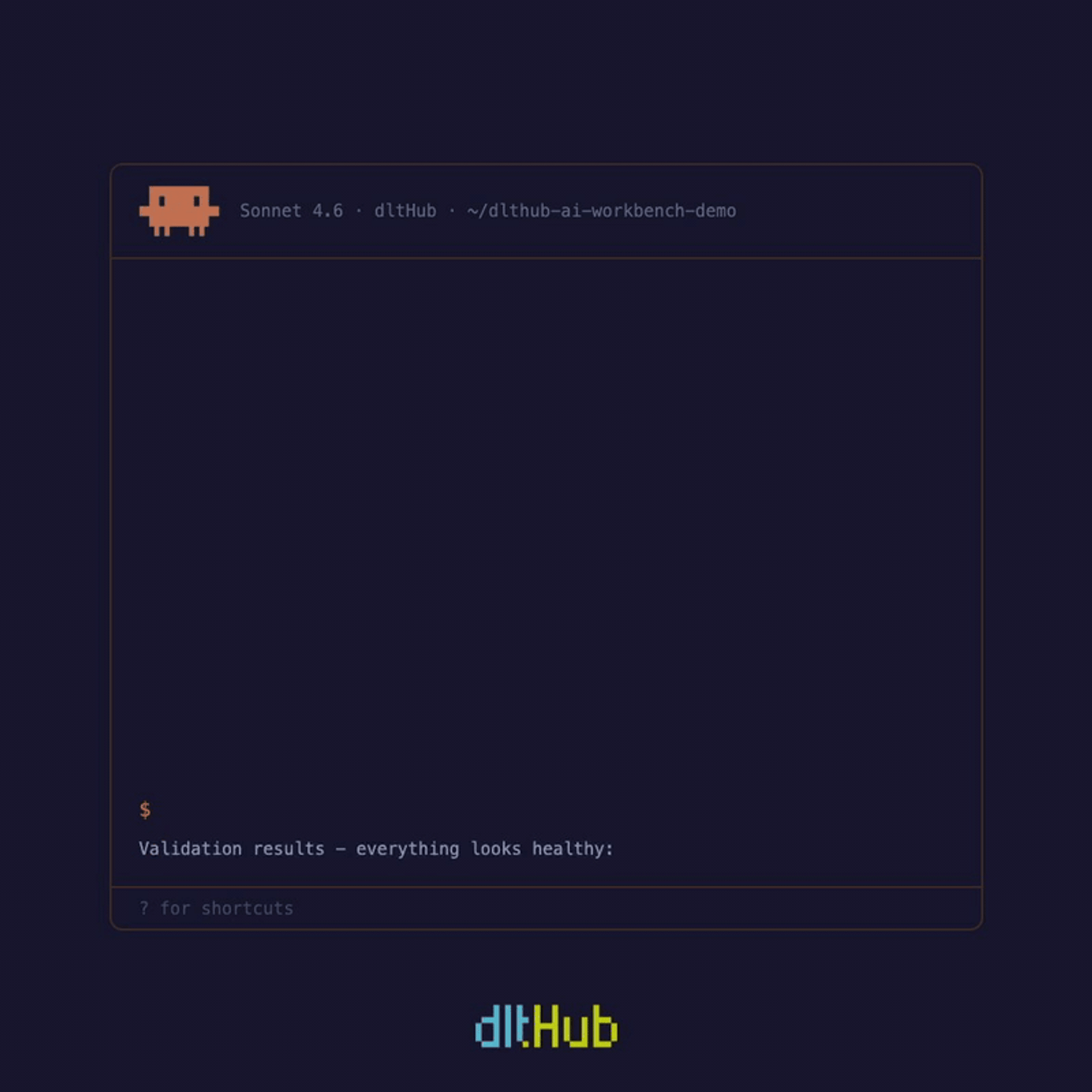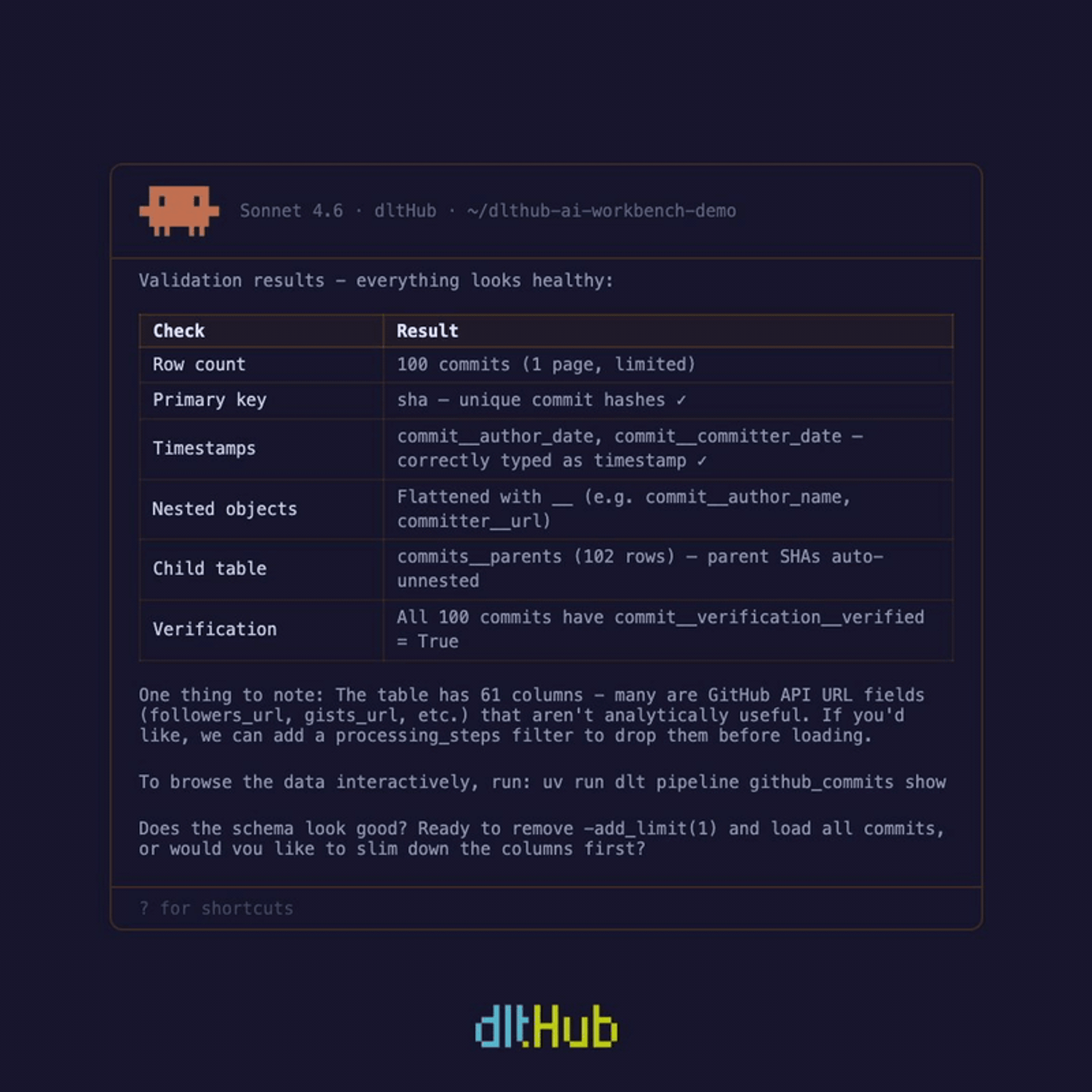
Ask for a dashboard and it generates a working Marimo notebook on the first attempt. The exploration toolkit closes the loop. You see what was ingested, spot issues, and fix them in the same session - without switching tools, without waiting on a cloud environment. The agent navigates between ingestion and exploration seamlessly. The feedback cycle is minutes, not days. This is what turns AI-assisted data engineering from a demo trick into something you'd actually use in production.
3. Data transformation toolkit
Instead of writing SQL transformations by hand, the agent helps you build an ontology of what your data actually means. Source tables get annotated with semantic context via a guided wizard. Those annotations map to a business taxonomy - so the platform knows what each source represents in your domain. Then the business taxonomy connects into a unified canonical model that ties your sources together and tells the agent how to combine them.
The ontology isn't just a semantic layer for dashboards. It's a reasoning substrate. An agent with access to this ontology isn't just enabled to retrieve metrics - it understands what data means in business context, and what can meaningfully be combined. Transformations in dltHub are driven by semantic understanding, not just code.
4. dltHub deployment toolkit
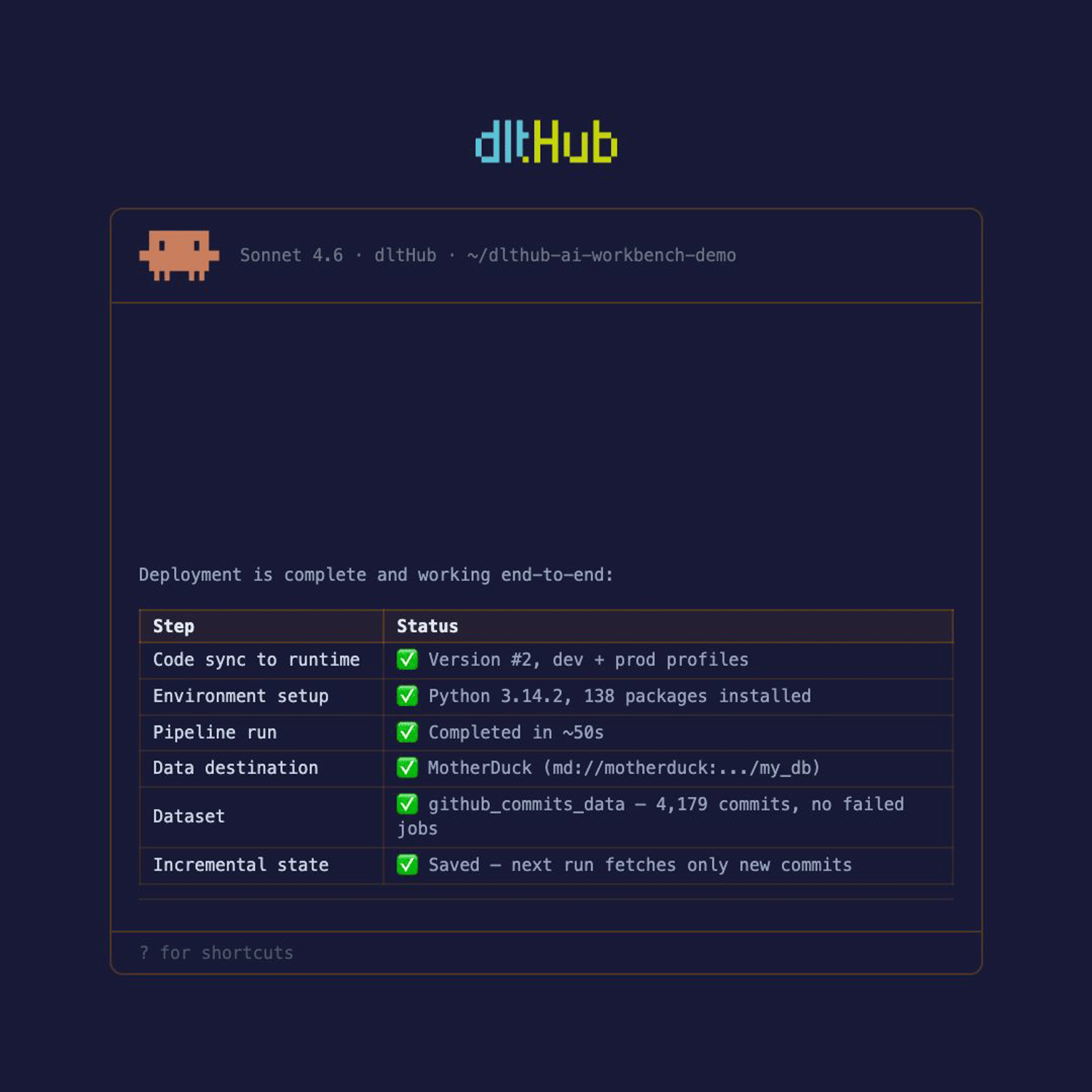
The deployment toolkit adds one capability the others don't have: taking a locally developed pipeline and deploying it to production.
What that actually involves is more than a deployment click. The agent runs three phases before anything moves to prod.
Convert to production workspace. Before deployment starts, the agent converts the dev workspace into a production-ready one. It creates separate dev and prod environment profiles, rewrites the pipeline to be destination-agnostic - you specify where data goes; the code doesn't hardcode it and pins all Python dependencies.
It then runs the pipeline in dev mode to confirm the converted code works end-to-end. It validates your production destination credentials without reading them - the toolchain exposes a validation tool that returns pass/fail.
The pipeline goes in as dev code and comes out ready to run in production.
Pre-deployment validation. Agent audits what has been just prepared for production deployment. It scans for development workflow artifacts. For example, dev_mode=True and .add_limit() calls are flagged and removed.
Deployment. Agent will carefully deploy your pipelines and notebooks and make sure that they work. It will launch jobs, read the logs, fix ie. missing dependencies or connections problems and re-deploy. Agent is able to use other toolkits, fix the pipeline, validate it on dev before going to production again.
Next day verification
You can continue deployment session the next day and ask agent for a health of your pipelines or status of the incremental loading of a particular resource. Agent is able to pull observability data via command line, inspect the logs and present you a report with an overview. If you enable agent to use “prod” profile (by pinning it) - it will be able to access production data which combined with observability allows it to debug common problems ie. incremental loading not producing data or generating duplicates.
Operational skills are our next frontier and current capabilities are based on the context that agent builds during deployment and command line support. Full observability interface and related mcp is coming soon.
III. dltHub: where it all clicks
Each toolkit is useful on its own. But the point of dltHub isn't the individual pieces - it's what happens when they run together.
Most AI-assisted data engineering today is clunky: you use one tool to generate a pipeline. A different tool to validate the data. Their agents don't share context and the metadata disappears between steps. You manually add metadata and hand off between phases and repeat instructions. The agent loses context at every boundary. Each step starts from groundhog day — the skill that built the pipeline knows nothing about the skill that validates the data, which knows nothing about the dashboard that's supposed to visualize it. The result is a string of disconnected actions that happen to be in the same terminal.
dltHub works differently: it produces metadata, schemas, runtime traces, and data contracts that the exploration toolkit can immediately read. When the exploration toolkit validates your data, it pulls table previews through the MCP server using the schema the pipeline already established. When you ask for a dashboard, the agent already knows the table structure, the column types, what was validated, what passed. There's no handover. There's no "let me re-examine what you have." The context flows.
This is what we mean by an end-to-end agentic system for writing, running, and deploying dlt pipelines in dltHub. Skills, metadata, code, and context operate as one system, rather than a set of separate capabilities stitched together with prompts.
IV. How it works in practice
(25min demo)
Generating the pipeline
Aashish opened a blank VS Code project — no documentation, no existing code — and typed one prompt: "Hey, help me collect all of the commits in the dlt repository."
The agent activated the REST API toolkit and immediately pulled context from dlthub.com/context, where it discovered two approaches: a verified GitHub source and the generic REST API pipeline approach. The agent laid out both options and waited for the human to decide.
Aashish chose the REST API path. The agent scaffolded the full pipeline — endpoint configuration, authentication, pagination, schema normalization — ran it, and loaded the first 100 commits into DuckDB for inspection. The only manual step Aashish did: pasting in a GitHub token.
Validating the data
When Aashish said "perform data validation," the exploration toolkit picked up — it used the MCP server to pull table previews automatically and produced a full validation table: row counts, primary key checks, timestamp verification, nested object inspection. Aashish never specified what to validate or how, but the agent created a comprehensive view to answer most questions that a data engineer would ask.
Validation looked clean, so he loaded all commits — 4,151 rows. Then he opened the dlt dashboard to see pipeline run history, table schema browser, live SQL interface.
Using the data
Then: "Build a dashboard with commits per contributor as a bar chart and commits over time monthly as a line chart." The agent wrote a Marimo notebook, spun up a local server, and both charts rendered correctly on the first attempt.
Deploying to production
Aashish typed: "Deploy this pipeline to production."
Before anything moved to prod, the agent ran workspace conversion. It created separate dev and prod environment profiles, rewrote the pipeline to be destination-agnostic — pulling the hardcoded DuckDB reference and replacing it with a configurable destination — inspected the Marimo notebook for production compatibility, and pinned every Python dependency. The agent confirmed the conversion was complete before moving on.
Then validation. The agent scanned the converted code for dev artifacts: no dev_mode=True, no .add_limit() calls. It ran the pipeline in dev mode against the converted codebase to confirm it worked end-to-end. Then it checked production destination credentials. Aashish configured the destination — the one manual step in this phase. The agent validated the credentials and returned pass. It never read them.
Then, and only then, it deployed.
Propose, verify, enforce: How Agents, humans and tools do best together
We watched agents write tens of thousands of dlt pipelines a month and realized something: the bottleneck in data engineering has moved. It's no longer writing the code. It's trusting the code. Knowing the schema is right. Knowing pagination didn't break silently. Knowing the pipeline is fit for production, not just fit for a demo.
Vibe coding and smarter prompts can't solve this. It takes infrastructure and the right information — a platform where hard tooling captures the context, metadata, and semantics that agents need to reason correctly, and where tight feedback cycles let humans verify what was produced.
That's the core design principle of dltHub: the platform continuously captures and propagates information — schemas, metadata, runtime traces, semantic annotations — and makes it available to both agents and humans at every step. The tooling generates the information. The agents reason with it. The humans verify it.
Three principles make this work:
Transparency - everything is code, context flows as metadata and schemas rather than disappearing into black-box abstractions.
Modularity and interoperability - the platform is a set of composable tools, not a monolith. DuckDB for local dev, Marimo for data apps, Ibis for transformations. Agents build from proven building blocks, and humans can pick what they need.
Human-in-the-loop control — agents propose, humans validate, and deterministic tooling enforces the boundaries where probabilistic isn't safe enough. Three explicit checkpoints in every workflow: you choose the approach, you supply credentials, you approve before anything goes to production.
The platform captures what needs to be captured. Schema inference and evolution track how your data is structured and when it changes. The dataset browser shows you exactly what was ingested. Pipeline observability gives you real-time traces. The ontology layer annotates what data means in business context. None of this is optional metadata you bolt on later — it's produced automatically as pipelines run, and it accumulates through the lifecycle.
Agents reason with that information. The richer the information the platform captures, the better the agent performs — because it's reading schemas, checking metadata, pulling context from the MCP server, and using semantic annotations to understand what it's working with.
Humans verify through tight feedback cycles. The local DuckDB workspace lets you prototype, browse raw data, validate, fix, and rerun — without switching tools. The dlt dashboard gives you pipeline history, schema browsing, and live SQL. Every piece of generated code is inspectable Python you can read and modify.
Trust in the agent's work is built into dltHub, not bolted on
When you let an agent build data pipelines, you're extending a lot of trust. The agent is working with your APIs, your data, your infrastructure. The question every engineering team asks is: what happens when it gets something wrong? We are building dltHub around that question.
The agent doesn't need your credentials or raw data to be smart. By separating data from metadata, the agent operates on schemas, table structures, and data shapes. For credentials, the agent uses deterministic CLI and specific functional tools. This way your agent knows if a connection works or what data is available without risking leas or prompt injections.
Systemic awareness of code and metadata makes agents and humans able to iterate safely. Everything dltHub produces is standard, inspectable Python. There is no proprietary "black box" or hidden logic, everything from code to traces are available to human or agent.
Underneath it all sits dlt: a library battle-tested across millions of runs. dlt’s resilience, schema evolution and data contracts are the fundamental DNA of the platform, ensuring your warehouse stays structured regardless of what wrote the code.
| Toolkit | What it does | Availability |
|---|---|---|
| bootstrap | Checks for uv, Python venv, and dlt; installs what's missing; then runs dlt ai init and lists available toolkits | Try it out yourself! Run /init-workspace |
| rest-api-pipeline | Scaffold, debug, and validate REST API ingestion pipelines | Try it out yourself! Run /find-source |
| data-exploration | Query loaded data and create marimo dashboards | Try it out yourself! Run /explore-data |
| dlthub-runtime | Deploy pipelines to the dltHub platform | Join early access |
| transformations | Design a Canonical Data Model (CDM) and write dlt transformation functions from existing pipelines | Join early access |
Start here
Launches such as this are also a byproduct of our design partnership program. We continue to share dltHub with a small number of builders whose judgment we trust. We want hands-on usage, feedback on the vision, and honest reactions. If you like it and want to keep using it, you'll get a heavy discount at public launch. If you don't, we need to know why.
Works with Claude Code, Cursor, and Codex.
A repo with the code can be found here: https://github.com/dlt-hub/dlthub-ai-workbench
uv pip install --upgrade "dlt[workspace]"
uv run dlt ai init